Understanding the Cell Microprocessor
by Anand Lal Shimpi on March 17, 2005 12:05 AM EST- Posted in
- CPUs
Blueprint for a High Performance per Transistor CPU
Given that Cell was designed with a high performance per transistor metric in mind, its architecture does serve as somewhat of a blueprint for the technologies that result in the biggest performance gains, at the lowest transistor counts. Now that we’ve gone through a lot of the Cell architecture, let’s take a look back at what some of those architectural decisions are:1. On-die memory controller
We’ve seen this with the Athlon 64, but an on-die memory controller appears to be one of the best ways to improve overall performance, at minimal transistor expenditure. Furthermore, we also see the use of Rambus’ XDR memory instead of conventional DDR, as the memory of choice for Cell. High frequencies and high bandwidth are what Cell thrives on, and for that, there’s no substitute but Rambus’ technology.
2. SMT
On-die multithreading has also been proven to be a good way of extracting performance at minimal transistor impact. Introducing Hyper Threading to the Pentium 4’s core required a die increase of less than 5%, just to give you an idea of the scale of things. The performance benefits to SMT will obviously vary depending on the architecture of the CPU. In the case of the Pentium 4, performance gains ranged from 0 - 20%. In the case of the in-order PPE core of Cell, the performance gains could be even more. Needless to say, if implemented well, and if proper OS/software support is there, SMT is a feature that makes sense and doesn’t strain the transistor budget.
3. Simpler, in-order, narrow-issue core - but lots of them
This next design decision is more controversial than the first two, simply because it goes against the design strategies of most current generation desktop microprocessors that we’re familiar with. By making the PPE and SPEs 2-issue only, each individual core still remains a manageable size. Narrower cores obviously sacrifice the ability to extract ILP, but doing so allows you to cram more cores onto a single die - highlighting the ILP for TLP sacrifice that the Cell architects have made.
Getting rid of the additional logic and windows needed for an out-of-order core helps further reduce transistor count, but at the expense of making sure that you have a solid compiler and/or developers that are willing to deal with more of the architecture’s intricacies to achieve good performance.
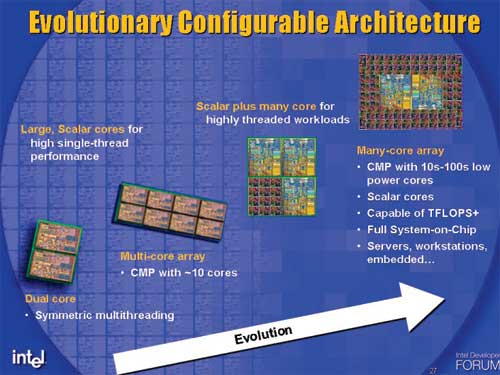
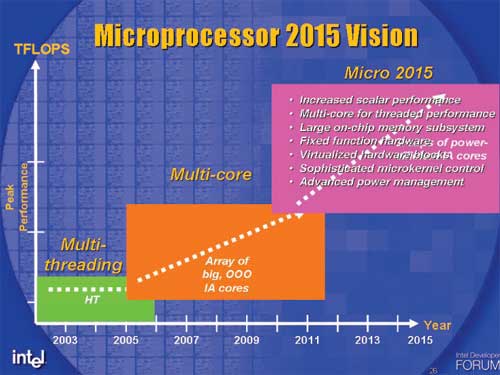
Looking at Intel’s roadmap for Platform 2015, the type of microprocessors that they’re talking about are eerily Cell-like - a handful of strong general purpose cores surrounded by smaller cores, some of which are more specialized hardware.








70 Comments
View All Comments
Poser - Thursday, March 17, 2005 - link
There were moments while reading this article that I expected there to be a "Test Yourself" quiz at the end of the chapter ... er, article. Which isn't to say that articles like this are too textbookish, it's to say that they're wonderfully educational. And very, very cool for being so.I'm half joking when I say this (but only half) -- a real "test" at the end of the article would be fun. I could see if I really understood what I read, and even get to compare my score to the rest of the, uhm, class.
drinkmorejava - Thursday, March 17, 2005 - link
very nice, how long did it take to write that thing?Eug - Thursday, March 17, 2005 - link
#42,That's an interesting page, cuz everyone on OS X already knows that Word is slow on the Mac. It brings us back to the original statement that some ported software may be problematic performance-wise.
And the generic comment on the Mac side about Premiere is, well... use Final Cut Pro. :) Here is a test that seems a bit more useful, since it tests Cinema4D and After Effects, two apps that people use on the Mac and both of which are reasonably well optimized:
http://digitalvideoediting.com/articles/viewarticl...
That's a good point about the memory scaling though. The IMC with AMD's chips is a definite advantage. I'm sure the G5 970MP dual-core won't get an IMC either.
Anyways, as far as this article is concerned, the G5 is kinda irrelevant. The interesting part for Apple in Cell is the PPE unit. It's also interesting that Anand says the original SPE was supposed to be VMX/Altivec. But the current SPE is not Altivec so it's less applicable for Apple, at least in the near term.
It would be interesting to know how fast a dual-core 3 GHz PPE would be in general laptop-type code, and how much power it would put out.
MDme - Thursday, March 17, 2005 - link
#39, 40, 41http://www.pcworld.com/news/article/0,aid,112749,p...
remember that the athlon 64 chips scale better at higher clock speeds due to the mem controller scaling as well.
Eug - Thursday, March 17, 2005 - link
Well, one example is Cinebench 2003:The dual G5 2.0 GHz is about the same speed as a dual 0pteron 246 2.0 GHz, with a score at around 500ish.
http://www.aceshardware.com/read.jsp?id=60000284
BTW, a dual G5 2.5 GHz scores 633.
suryad - Thursday, March 17, 2005 - link
Hmm that is interesting what you say Eug. I see your point do you have any links on straight comparos between an FX and a top of the line Mac? Or from personal experience folding and such...Eug - Thursday, March 17, 2005 - link
#38. It's a mistake to say an AMD FX 55 smokes a dual G5 2.5. For instance, if you like scientific dual-threaded stuff, the G5 does very well. However, the AMD FX 55 IS faster than a single G5 2.5. It's got a slight edge clock-for-clock, and it's clocked slightly higher too.The real problem is when you have stuff built for x86 ported over to PPC. It just isn't great on the Mac side performance-wise in that situation. And Macs aren't tweaked for gaming either. The AMD is going to smoke the Mac in Doom 3 of course.
I think with the performance advantage of the Opteron, I'd put a single G5 2.5 in the range of performance of a single Opteron 2.2-2.4 GHz, depending on the app. The real interesting part though will be the coming quarter, when the new G5s are released. They should get a significant clock speed bump (20%?) and information on dual-core G5s are already out there (like with AMD and their dual-core Athlons). They also get a cache boost. Right now they only have 512 KB, but are expected to get 1 MB L2.
suryad - Thursday, March 17, 2005 - link
Well scrotemaninov I am not disputing that the POWER architecture by IBM is brilliantly done. IBM is definitely one of those companies churning out brilliant and elegant technology always in the background.But my problem with the POWER technology is from what I understand very limitedly, is that the POWER processors in the Mac machines are a derivative of that architecture right? Why the heck are they so damn slow then?
I mean you can buy an AMD FX 55 based on the crappy legacy x86 arch and it smokes the dual 2.5 GHz Macs easily!! Is it cause of the OS? Because so far from what I have seen, if the Macs are any indication of the performance capabilities of the POWER architecture, the Cell will not be a big hit.
I did read though at www.aceshardware.com benchmark reviews of the POWER5 architecture with some insane number of cores if I recall correctly and the benchmarks were of the charts. They are definitely not what the Macs have installed in them...
scrotemaninov - Thursday, March 17, 2005 - link
#35: different approaches to solving the same problem.Intel came up with x86 a long time ago and it's complete rubbish but they maintain it for backwards compatibility (here's an argument for Open Source Software if ever there was one...). They have huge amounts of logic to effectively translate x86 into RISC instructions - look at the L1I Trace Cache in the P4 for example.
IBM aren't bound by the same constraints - their PowerPC ISA is really quite nice and so there's no where near the same amount of pain suffered trying to deal with the same problem. It does seem however, that IBM are almost at the point that Intel want to be in 10 years time...
Verdant - Thursday, March 17, 2005 - link
here is a question...it mentions (or alludes) in the article that having no cache means that knowing exactly when an instruction would be executed is possible, is the memory interface therefore a strict "real time system" ?