i5 / P55 Lab Update - Now with more numbers
by Gary Key on September 15, 2009 12:05 AM EST- Posted in
- Motherboards
Multitasking-
The vast majority of our benchmarks are single task events that utilize anywhere from 23MB up to 1.4GB of memory space during the course of the benchmark. Obviously, this is not enough to fully stress test our 6GB or 8GB memory configurations. We devised a benchmark that would simulate a typical home workstation and consume as much of the 6GB/8GB as possible without crashing the machine.
We start by opening two instances of Internet Explorer 8.0 each with six tabs opened to flash intensive websites followed by Adobe Reader 9.1 with a rather large PDF document open, and iTunes 8 blaring the music selection of the day loudly. We then open two instances of Lightwave 3D 9.6 with our standard animation, Cinema 4D R11 with the benchmark scene, Microsoft Excel and Word 2007 with large documents, and finally Photoshop CS4 x64 with our test image.
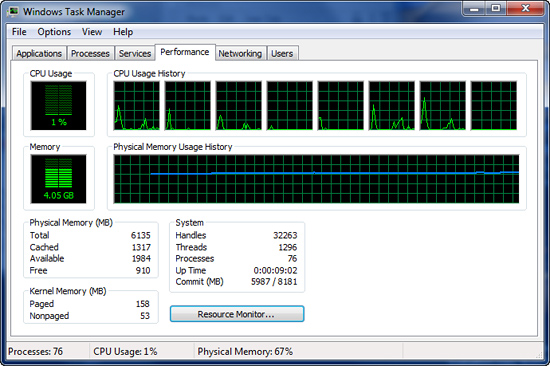
Before we start the benchmark process, our idle state memory usage is 4.05GB. Sa-weet!
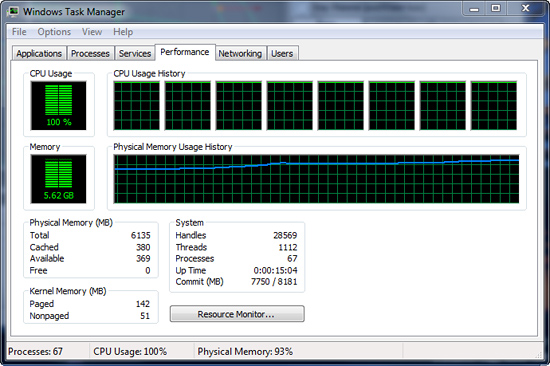
We wait two minutes for system activities to idle and then start playing Pinball Wizard via iTunes, start the render scene process in Cinema 4D R11, start a resize of our Photoshop image, and finally the render frame benchmark in Lightwave 3D. Our maximum memory usage during the benchmark is 5.62GB with 100% CPU utilization across all four or eight threads.


So far, our results have pretty much been a shampoo, rinse, and repeat event. I believe multitasking is what separates good systems from the not so good systems. I spend very little time using my system for gaming and when I do game, everything else is shutdown to maximize frame rates. Otherwise, I usually have a dozen or so browser windows open, music playing, several IM programs open and in use, Office apps, and various video/audio applications open in the background.
One or two of those primary applications are normally doing something simultaneously, especially when working. As such, I usually find this scenario to be one of the most demanding on a computer that is actually utilized for something besides trying to get a few benchmark sprints run before the LN2 pot goes dry.
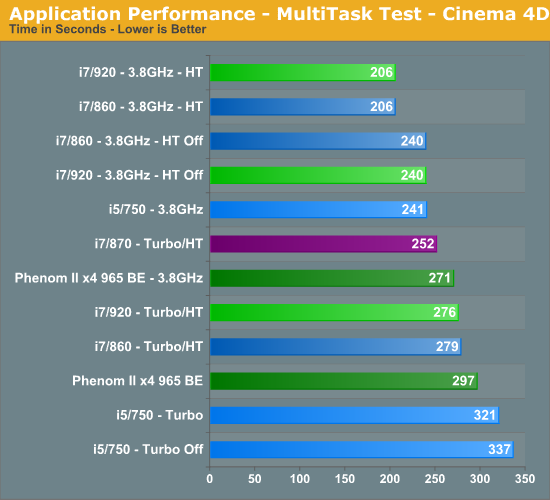
The i5/750 results actually surprised me. The system never once felt “slow” but the results do not lie. The i5/750 had its head served on a platter at stock speeds, primarily due to the lack of Hyper-Threading when compared to the other choices. The 965 BE put up very respectable numbers and scaled linearly based on clock speed. An 11% increase in clock speed resulted in a 10% improvement in the total benchmark score for the 965 BE. You cannot ask for more than that.
At 3.8GHz clock speeds, it is once again a tossup between the 920 and 860 processors with HT enabled. The 920 did hold a slight advantage over the 860 at stock clock settings, attributable to slightly better data throughput when under load conditions. Otherwise, on the Intel side the i7/870 provided excellent results based on its aggressive turbo mode, although at a price.
Gaming-
We utilize the Ranch Small demo file along with the FarCry 2 benchmark utility. This particular demo offers a balance of both GPU and CPU performance.

We utilize FRAPS to capture our results in a very repeatable section of the game and report the median score of our five benchmark runs. H.A.W.X. responds well to memory bandwidth improvements and scales linearly with CPU and GPU clock increases.
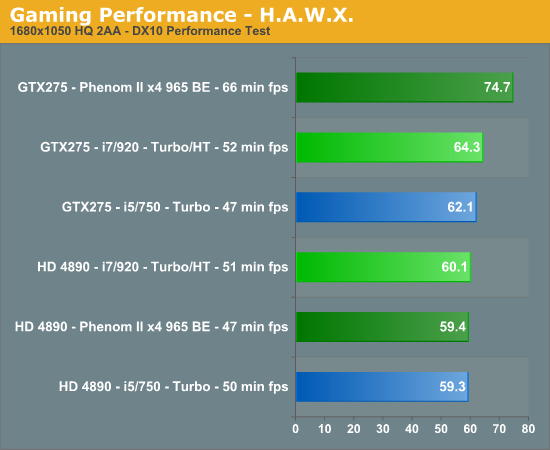
Your eyes are not deceiving you. After 100+ clean OS installs, countless video card, motherboard, memory and driver combinations, we have results that are not only repeatable, but appear to be valid. We also tracked in-game performance with FRAPS and had similar results. Put simply, unless we have something odd going on with driver optimizations, a BIOS bug, or a glitch in the OS, our NV cards perform better on the AMD platform than they do on the Intel platform. The pattern reverses itself when we utilize the AMD video cards.
It is items like this that make you lose hair and delay articles. Neither of which I can afford to have happen. However, we have several suppliers assisting us with the problem (if it is a problem) and hope to have an answer shortly. These results also repeat themselves in other games like H.A.W.X. and Left 4 Dead but not in Crysis Warhead or Dawn of War II. So, besides the gaming situation, we also see a similar pattern in AutoCad 2010 and other 3D rendering applications where GPU acceleration is utilized, it is just not as pronounced.








77 Comments
View All Comments
crimson117 - Tuesday, September 15, 2009 - link
"It is items like this that make you lose hair and delay articles. Neither of which I can afford to have happen."Thank you for making me almost choke on the scone I was eating.
Ocire - Tuesday, September 15, 2009 - link
That's some strange numbers you got there...Just an idea that popped up my mind: Could effective PCIe bandwidth be the key here?
You can do the bandwidth test that comes with nVIDIAs CUDA with the shmoo-option for pinned and unpinned memory on both platforms.
If you get higher numbers on the AMD platform, it could be that with P55 and X58 the card is in some cases interface bandwidth bound. (Which isn't that uncommon in some GPGPU applications, too)
Holly - Tuesday, September 15, 2009 - link
I was thinking about bandwidth as well, but then I realised with P55 CPU has direct lanes to first PCIe 16x slot while X58 platform runs via Northbridge... It's way too different approach to both produce same problem imho...This seems like driver issue to me. Maybe the CPU and GPU parts of the engine+drivers run asynchronous and communication in between gets suffocated (st like i7 manages to compute too fast and data have to wait for next loop to go through)...
no clue though, it's just my best guess...
TA152H - Tuesday, September 15, 2009 - link
A lot of people are getting confused by the PCIe being on the processor as opposed to the Northbridge. Because the IMC shows advantages on the processor die in terms of memory latency, and moving the floating point unit did with the 486, it's assumed moving things onto the processor die should be faster. If you look closer though, it becomes clear this just isn't so.The reason the memory controller on the processor has advantages comes down to two important considerations - it's transferring to and from the processor, and it's got finer granularity than something running at lower clock speeds.
Let's look at the second first. Let's say I'm running the processor at eight times the speed of the northbridge. The number isn't so important, and it doesn't even have to be an integer, to illustrate the point, so I'm just picking one out of the air.
Let's call clock cycle eight the one where the northbridge also gets a cycle and can work on the request from the processor, and for the sake of simplicity, the memory controller can work on it. If I get something on processor cycles one through seven, I could start the memory read on the IMC, but the slower clock speed doesn't that level of granularity, so the read, or write, request waits. This is a gross oversimplification, but you probably get the point.
Perhaps more importantly, you're transferring from memory, to the processor. It's too the actual device the memory controller is attached to. And since the memory controller is on the processor itself, there's less overhead in getting generating the request to the memory controller.
The PCIe 16 slot is a different animal. You're not generally using the processor for this, except for now. It's going from one device, typically to memory, with possible disastrous consequences for the brain-damaged Lynnfield line.
With a proper setup, there wouldn't be any real difference. I'm not sure how the Lynnfield is set up though, and I'm not sure it's a proper setup like the x58. I'll explain. If we look at the x58, the video card will transfer memory to the Northbridge, and then the Northbridge will interface to the memory. It has channels on it to do that, and it doesn't involve the processor at all, or need to.
On the Lynnfield, now you're involving the processor, for no good reason except for cost (which is a really good reason, actually). So, now the video card sends a request to the PCIe section of the processor, and the processor has to do the transfer. Now, this is the big question - just how brain-damaged is the Lynnfield? Does it actually have a seperate path to handle these transfers, or does it basically multiplex the existing narrow memory bus to handle these? It's almost certainly the latter, since I don't know how much sense it would make to only use part of the memory bus for all other transfers. Anand can hopefully answer these questions, although this site tends to never look very deep at things like this, so I'm doubtful. I guess they don't think we're interested, but I surely am.
The end result is, you could have competition for the already narrower memory bus, where the processor can get locked out of it while PCIe transfers are going on. This is consistent with some benchmarks other sites show, where the Lynnfield struggles more than it should on games.
I don't want to make this sound worse than it is though. Most video cards have a lot of memory, and the actual number of requests to memory hopefully isn't very high. Even on a Bloomfield, any request to main memory is a slow down since video memory will always be faster. Also, cards will keep getting more memory, whereas the human eye is not going to get able to discern better resolution, so presumably cards will not have to use main memory at all, in the future. And, keep in mind, processors have big L3 caches, so don't need to go out to memory all that often. So, it's not catastrophic, but you should see it, and more as you stress the CPU and GPU. Again, if you look at other websites that did some serious game stressing, you do see the Bloomfields distance themselves from their brain-damaged siblings as you stress the system more.
yacoub - Tuesday, September 15, 2009 - link
I think we'd all be interested to know the answer to this quandary, however I also think you're exaggerating a bit when you call it brain damaged and say things like "disastrous consequences". In reality what you mean is that in extreme bandwidth saturation situations like SLI it's possible it might be slower than X58, and maybe when the DX11 generation of cards come out they will actually require enough bandwidth for it to be even more noticeable in SLI comparisons. But for the vast majority of us who run a single GPU, so long as a single DX11 card doesn't fully saturate the available bus bandwidth and thus doesn't perform any less than on X58, P55 is just fine.TA152H - Wednesday, September 16, 2009 - link
I agree, when I was typing it, I meant disastrous consequences with respect to that particular instance when the processor has to multiplex. In the context of overall performance, I don't think it would be that huge. I wasn't clear about that.But, you're off with regards to the saturation. You don't have to saturate the bus, at all. You don't need two cards. That type of thinking is fallacious, in that it assumes only part of the bus is used.
In reality, ANY time the video card needs the memory bus, and the processor needs to read memory, you've got a collision, and one or the other has to wait. This would happen more often if you have more stress on the processors, or video subcomponent, but could happen even with one card, and one processor being used. It just would be much less frequent, and probably insignificant.
These are the type of compromises these web sites should be bringing up, but they simply don't. It's not just this one, but shouldn't a tech site bring up questions like this, instead of just publish benchmarks (which, as we know, are far from objective and can paint a different picture based on the parameters and benchmarks chosen).
I wouldn't expect this from PC Magazine, but from 'tech' sites? They just aren't very technical.
Gary Key - Tuesday, September 15, 2009 - link
P55 will be just fine with the DX11 cards.. whistles and grins evilly looking at the results, however, for top performance in SLI or CF, it is X58 all the way. That said, I have not been able to tell the difference between 130 FPS and 128 FPS in HAWX yet, nor between 211 FPS and 208 FPS in L4D. :)jonup - Wednesday, September 16, 2009 - link
does your comment mean that you have/have seen a HD 5870 in action?yacoub - Tuesday, September 15, 2009 - link
It appears more driver/optimization-related given that some games that are less bandwidth-intensive are showing the strange performance and others are not.yacoub - Tuesday, September 15, 2009 - link
Hey I wonder if Gary tried renaming the .exe just to see if it was a driver bug with certain game engine optimizations! :)