NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
Efficiency Gets Another Boon: Parallel Kernel Support
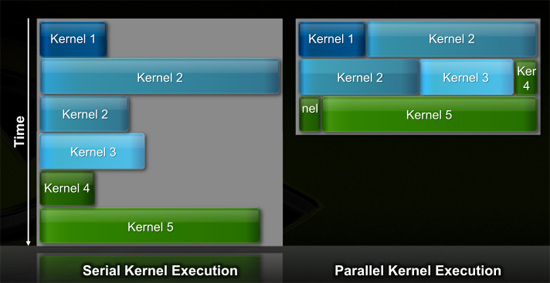
In GPU programming, a kernel is the function or small program running across the GPU hardware. Kernels are parallel in nature and perform the same task(s) on a very large dataset.
Typically, companies like NVIDIA don't disclose their hardware limitations until a developer bumps into one of them. In GT200/G80, the entire chip could only be working on one kernel at a time.
When dealing with graphics this isn't usually a problem. There are millions of pixels to render. The problem is wider than the machine. But as you start to do more general purpose computing, not all kernels are going to be wide enough to fill the entire machine. If a single kernel couldn't fill every SM with threads/instructions, then those SMs just went idle. That's bad.
GT200 (left) vs. Fermi (right)
Fermi, once again, fixes this. Fermi's global dispatch logic can now issue multiple kernels in parallel to the entire system. At more than twice the size of GT200, the likelihood of idle SMs went up tremendously. NVIDIA needs to be able to dispatch multiple kernels in parallel to keep Fermi fed.
Application switch time (moving between GPU and CUDA mode) is also much faster on Fermi. NVIDIA says the transition is now 10x faster than GT200, and fast enough to be performed multiple times within a single frame. This is very important for implementing more elaborate GPU accelerated physics (or PhysX, great ;)…).
The connections to the outside world have also been improved. Fermi now supports parallel transfers to/from the CPU. Previously CPU->GPU and GPU->CPU transfers had to happen serially.








415 Comments
View All Comments
shotage - Thursday, October 1, 2009 - link
lol*shakes head*
palladium - Thursday, October 1, 2009 - link
Ahh, he said a 9800 GTX + GDDR5 = 4870 !blindbox - Thursday, October 1, 2009 - link
Ooops, I think I need to speak something on topic at least. Anyone could tell me if OpenCL SDK is out yet? Or DirectCompute too? It has been over a year since GPU computing was announced and nothing useful for the consumers (I don't call folding for consumers).habibo - Thursday, October 1, 2009 - link
Yes, both OpenCL and DirectCompute are available for development. It will take time for developers to release applications that use these APIs.There are already consumer applications that use CUDA, although these are mostly video encoding, Folding@Home/SETI@home, and PhysX-based games. Possibly not too exciting to you, but hopefully more will be coming as GPU computing gains traction.
PorscheRacer - Thursday, October 1, 2009 - link
Does anyone know if the 5000 series support hardware virtualisation? I think this will be the killer feature once AMD's 800 series chipsets debut here shortly. Being able to virtualise the GPU and other hardware with your virtual machines is the last stop to pure bliss.dgz - Thursday, October 1, 2009 - link
I am also curious. Right now only nVidia's Quadro cards support this.The thing is, though, that your CPU and chipset also have to support what Intel calls VT-d.
Being able to play 3D games in virtual OS with little to no performance would be great and useful.
Not going to happen soon, though. It's also funny that virtually no one Lynnfield mentioned the lack of VT-d in 750 in his "deep" review. Huge disappointment.
wifiwolf - Thursday, October 1, 2009 - link
If there's any technology that seams to scratch that virtualization, i think this new gt300 is the one. When reading about nvidia making the card compute oriented it just drove my mind to that thought. Hope i'm right. To be fair with amd, i think their doubled stream processors could be a step forward in that direction too, coupled with dx11 direct compute. Virtual machines just need to acknowledge the cards and capabilities.dgz - Friday, October 2, 2009 - link
They already do. vmware and vbox have such capabilities. Not everything is possible atm, though.dgz - Thursday, October 1, 2009 - link
oops, I meant "little to no performance penalty" :)sigmatau - Thursday, October 1, 2009 - link
According to the super troll who keeps screeching about bandwidth, then the GT300 must be a lesser card since it doesn't have 512 bit connection like the GT200.LOL @ Trolls.