NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
Architecting Fermi: More Than 2x GT200
NVIDIA keeps referring to Fermi as a brand new architecture, while calling GT200 (and RV870) bigger versions of their predecessors with a few added features. Marginalizing the efforts required to build any multi-billion transistor chip is just silly, to an extent all of these GPUs have been significantly redesigned.
At a high level, Fermi doesn't look much different than a bigger GT200. NVIDIA is committed to its scalar architecture for the foreseeable future. In fact, its one op per clock per core philosophy comes from a basic desire to execute single threaded programs as quickly as possible. Remember, these are compute and graphics chips. NVIDIA sees no benefit in building a 16-wide or 5-wide core as the basis of its architectures, although we may see a bit more flexibility at the core level in the future.
Despite the similarities, large parts of the architecture have evolved. The redesign happened at low as the core level. NVIDIA used to call these SPs (Streaming Processors), now they call them CUDA Cores, I’m going to call them cores.
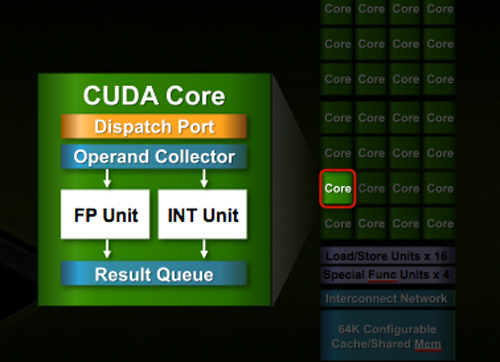
All of the processing done at the core level is now to IEEE spec. That’s IEEE-754 2008 for floating point math (same as RV870/5870) and full 32-bit for integers. In the past 32-bit integer multiplies had to be emulated, the hardware could only do 24-bit integer muls. That silliness is now gone. Fused Multiply Add is also included. The goal was to avoid doing any cheesy tricks to implement math. Everything should be industry standards compliant and give you the results that you’d expect.
Double precision floating point (FP64) performance is improved tremendously. Peak 64-bit FP execution rate is now 1/2 of 32-bit FP, it used to be 1/8 (AMD's is 1/5). Wow.
NVIDIA isn’t disclosing clock speeds yet, so we don’t know exactly what that rate is yet.
In G80 and GT200 NVIDIA grouped eight cores into what it called an SM. With Fermi, you get 32 cores per SM.
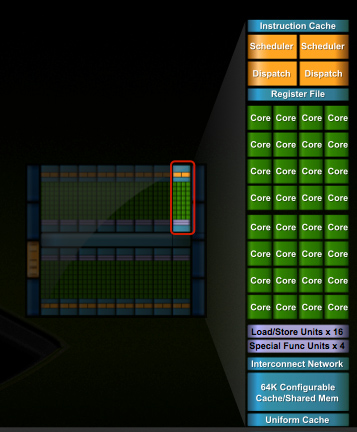
The high end single-GPU Fermi configuration will have 16 SMs. That’s fewer SMs than GT200, but more cores. 512 to be exact. Fermi has more than twice the core count of the GeForce GTX 285.
| Fermi | GT200 | G80 | |
| Cores | 512 | 240 | 128 |
| Memory Interface | 384-bit GDDR5 | 512-bit GDDR3 | 384-bit GDDR3 |
In addition to the cores, each SM has a Special Function Unit (SFU) used for transcendental math and interpolation. In GT200 this SFU had two pipelines, in Fermi it has four. While NVIDIA increased general math horsepower by 4x per SM, SFU resources only doubled.
The infamous missing MUL has been pulled out of the SFU, we shouldn’t have to quote peak single and dual-issue arithmetic rates any longer for NVIDIA GPUs.
NVIDIA organizes these SMs into TPCs, but the exact hierarchy isn’t being disclosed today. With the launch's Tesla focus we also don't know specific on ROPs, texture filtering or anything else related to 3D graphics. Boo.
A Real Cache Hierarchy
Each SM in GT200 had 16KB of shared memory that could be used by all of the cores. This wasn’t a cache, but rather software managed memory. The application would have to knowingly move data in and out of it. The benefit here is predictability, you always know if something is in shared memory because you put it there. The downside is it doesn’t work so well if the application isn’t very predictable.
Branch heavy applications and many of the general purpose compute applications that NVIDIA is going after need a real cache. So with Fermi at 40nm, NVIDIA gave them a real cache.
Attached to each SM is 64KB of configurable memory. It can be partitioned as 16KB/48KB or 48KB/16KB; one partition is shared memory, the other partition is an L1 cache. The 16KB minimum partition means that applications written for GT200 that require 16KB of shared memory will still work just fine on Fermi. If your app prefers shared memory, it gets 3x the space in Fermi. If your application could really benefit from a cache, Fermi now delivers that as well. GT200 did have an L1 texture cache (one per TPC), but the cache was mostly useless when the GPU ran in compute mode.

The entire chip shares a 768KB L2 cache. The result is a reduced penalty for doing an atomic memory op, Fermi is 5 - 20x faster here than GT200.








415 Comments
View All Comments
rennya - Thursday, October 1, 2009 - link
Here in SE Asia, 5870 GPU is available in abundance in retail channels. If you PayPal me USD450, I can go straight to any of the computer shops I passed when I go to work, so that I can buy the card (and a casing that will fit the full length card), then I can take pictures and show it to you.Stop it with the claims that the 5870 launch is just a paper launch. That patently isn't true, and will only make you look stupid.
SiliconDoc - Thursday, October 1, 2009 - link
I'm sure your email box is overflowing with requests, and I'm sure your walk to work will serve all the customers around the world.Thanks for that great bit of information for those walking to work with you in SE asia, I bet they're really happy.
---
Maybe you should get a Reseller ID, and make that millionaire dream of yours come true, and soon when rooster central flaps it up again, you can prove to the world dry as a bone ain't rice paper.
---
No, one cannot really fathom the insanity, and red rooster doesn't describe the thickness of skull properly at all, merely the size of it's contents.
rennya - Friday, October 2, 2009 - link
Nope, my inbox is not overflowing with requests, because after all, anyone who wants a 5870 GPU, will be able to get it.If you cannot prove that 5870 is a paper launch, maybe you should shut up your shop?
Sozo - Thursday, October 1, 2009 - link
If we are "red roosters" what does that make you? The green grizzly?SiliconDoc - Thursday, October 1, 2009 - link
Actually the first person to offer any thought on the matter suggested green goblin, which was a decent attempt, since grizzly bears aren't green, and goblins have a much better chance of being so.Howver, if you'd the actual nvidia equivalence of what you ati red roosters are, I'd be happy to provide some examples for you, which I have not done as of yet, and of course you're all too stupid rah-rah to even fathom that. That's pretty sad, and only confirms the problem. I'm certain you can't understand, so don't bother yourself.
http://www.fudzilla.com/content/view/15762/1">http://www.fudzilla.com/content/view/15762/1
silverblue - Thursday, October 1, 2009 - link
What sort of rooster are we talking? I mean, a Sussex rooster is almost exclusively not red. Can I be that one, please?Now THAT's trolling.
Natfly - Thursday, October 1, 2009 - link
I'm thinking a green goober.SiliconDoc - Thursday, October 1, 2009 - link
If you even believed your own pile of fud, you'd go to page 2 I believe it is in the article and see where anand says " sorry that's all we know about the GT300 the game card, nvidia won't tell us anymore"What he was told is IT'S FASTER THAN 5870, and the cores have already been cut, and the cards already under test.
So we already know, if we aren't a raging red doofus, and of course, that is very difficult for almost everyone here.
Also, this was not an official launch date for NVidia, they never declared it as such, just Anand delcared it in his article.
The official launch date for GT300 already spoken about multiple times by the aithors of this website is !!! > THE RELEASE DATE OF WINDOWS 7...
Now, wether nvidia changes their official launch date before then or not, or where the authors got that former information, one can surmise, but changing their AT tune about nvidia in an article title, for a conference and a web video atttendance, in order to appease the shamed and embarrased 3rd time in a row paper launching ati, 4870,4770, 5870, is not "unbiased" nor is it honest, no matter how much you want it to be.
If a person wants to claim it's a planned LEAK to showcase upcoming tech ( nvidia did this AFTER the GT300 gpu cores reported GOOD YIELD) - and combat fools purchasing the epic failure 5870 instead of waiting for the gold, ok.
siyabongazulu - Friday, October 2, 2009 - link
WOw wow wow!! You sir must be the most ignorant, manipulative, underappreciating, bastard.. sorry for tearing your world but you deserve such credentials and a lot more that can be given to people who display your kind of behaviour.You have been crying bias for no reason at all. If Anand says its paper launch, and if tgdaily says its paper launch (http://www.tgdaily.com/content/view/44157/135/)">http://www.tgdaily.com/content/view/44157/135/) and fudzilla (http://www.fudzilla.com/content/view/15762/1/)">http://www.fudzilla.com/content/view/15762/1/) which seems to be your favourite source so far doesn't even speak of anything but a display model that only confirms that GT300 is under construction.
So the only source you can come up with is yourself and you said it here and I quote "If you even believed your own pile of fud, you'd go to page 2 I believe it is in the article and see where anand says " sorry that's all we know about the GT300 the game card, nvidia won't tell us anymore"
What he was told is IT'S FASTER THAN 5870, and the cores have already been cut, and the cards already under test. " Those are your words, not NVIDIAs, no Anand, not Fudzilla, not from any other reviwers but yours.
Therefore, can you please STFU and stop trying to label everyone a red nosed rooster or whatever the f*** u call them.
P.S Not everyone appreciate your level of stupidity and before you can go and say geez there goes another one, FIY I'm running my system on Nvidia card and will buy ATI and snould NVIDIA "Physically Launch" GT300 and prove it to be better then already launched and benchamrked 5870 then you can come back and start your ranting. Until then plug that sh** hole of yours
MonkeyPaw - Thursday, October 1, 2009 - link
Dude, you take this way too personally. Do you have the same burning passion for real problems?