NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
Architecting Fermi: More Than 2x GT200
NVIDIA keeps referring to Fermi as a brand new architecture, while calling GT200 (and RV870) bigger versions of their predecessors with a few added features. Marginalizing the efforts required to build any multi-billion transistor chip is just silly, to an extent all of these GPUs have been significantly redesigned.
At a high level, Fermi doesn't look much different than a bigger GT200. NVIDIA is committed to its scalar architecture for the foreseeable future. In fact, its one op per clock per core philosophy comes from a basic desire to execute single threaded programs as quickly as possible. Remember, these are compute and graphics chips. NVIDIA sees no benefit in building a 16-wide or 5-wide core as the basis of its architectures, although we may see a bit more flexibility at the core level in the future.
Despite the similarities, large parts of the architecture have evolved. The redesign happened at low as the core level. NVIDIA used to call these SPs (Streaming Processors), now they call them CUDA Cores, I’m going to call them cores.
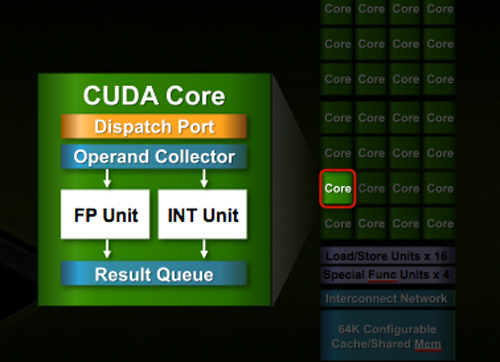
All of the processing done at the core level is now to IEEE spec. That’s IEEE-754 2008 for floating point math (same as RV870/5870) and full 32-bit for integers. In the past 32-bit integer multiplies had to be emulated, the hardware could only do 24-bit integer muls. That silliness is now gone. Fused Multiply Add is also included. The goal was to avoid doing any cheesy tricks to implement math. Everything should be industry standards compliant and give you the results that you’d expect.
Double precision floating point (FP64) performance is improved tremendously. Peak 64-bit FP execution rate is now 1/2 of 32-bit FP, it used to be 1/8 (AMD's is 1/5). Wow.
NVIDIA isn’t disclosing clock speeds yet, so we don’t know exactly what that rate is yet.
In G80 and GT200 NVIDIA grouped eight cores into what it called an SM. With Fermi, you get 32 cores per SM.
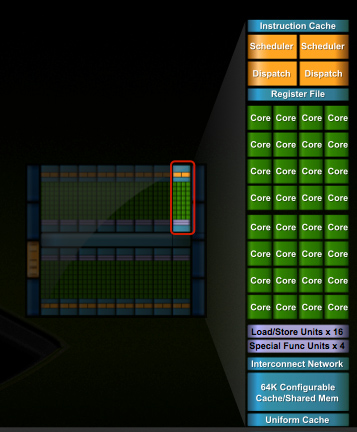
The high end single-GPU Fermi configuration will have 16 SMs. That’s fewer SMs than GT200, but more cores. 512 to be exact. Fermi has more than twice the core count of the GeForce GTX 285.
| Fermi | GT200 | G80 | |
| Cores | 512 | 240 | 128 |
| Memory Interface | 384-bit GDDR5 | 512-bit GDDR3 | 384-bit GDDR3 |
In addition to the cores, each SM has a Special Function Unit (SFU) used for transcendental math and interpolation. In GT200 this SFU had two pipelines, in Fermi it has four. While NVIDIA increased general math horsepower by 4x per SM, SFU resources only doubled.
The infamous missing MUL has been pulled out of the SFU, we shouldn’t have to quote peak single and dual-issue arithmetic rates any longer for NVIDIA GPUs.
NVIDIA organizes these SMs into TPCs, but the exact hierarchy isn’t being disclosed today. With the launch's Tesla focus we also don't know specific on ROPs, texture filtering or anything else related to 3D graphics. Boo.
A Real Cache Hierarchy
Each SM in GT200 had 16KB of shared memory that could be used by all of the cores. This wasn’t a cache, but rather software managed memory. The application would have to knowingly move data in and out of it. The benefit here is predictability, you always know if something is in shared memory because you put it there. The downside is it doesn’t work so well if the application isn’t very predictable.
Branch heavy applications and many of the general purpose compute applications that NVIDIA is going after need a real cache. So with Fermi at 40nm, NVIDIA gave them a real cache.
Attached to each SM is 64KB of configurable memory. It can be partitioned as 16KB/48KB or 48KB/16KB; one partition is shared memory, the other partition is an L1 cache. The 16KB minimum partition means that applications written for GT200 that require 16KB of shared memory will still work just fine on Fermi. If your app prefers shared memory, it gets 3x the space in Fermi. If your application could really benefit from a cache, Fermi now delivers that as well. GT200 did have an L1 texture cache (one per TPC), but the cache was mostly useless when the GPU ran in compute mode.

The entire chip shares a 768KB L2 cache. The result is a reduced penalty for doing an atomic memory op, Fermi is 5 - 20x faster here than GT200.








415 Comments
View All Comments
SiliconDoc - Thursday, October 1, 2009 - link
Nice consolation speech.I guess you expected " you're right ", but somehow lying to make you feel good is not in my playbook.
Now, next time you don't take it so seriously as to reply, and then still, be pathetic enough to get it wrong. Hows that for a fun deal ?
Maian - Wednesday, September 30, 2009 - link
Where's snakeoil when you need him... I don't give a shit about vendor, but the flame wars here are hilarious :DLifted - Wednesday, September 30, 2009 - link
What flame war? It's just a single nut barking at everyone for no reason. If he has a problem with the article he's sure making it difficult to figure out what it is with all his carrying on and red rooster nonsense.Does anyone (besides the nut) actually care what is said in this article? It's simply something to pass the time with, and certainly not worth getting upset over. Is the nut part of the nvidia marketing machine or merely a troll? It almost seems as if he's writing in a manner as to cover up his true identity. Yes silicondoc, it IS that obvious.
SiliconDoc - Thursday, October 1, 2009 - link
Wow, a conspiracist.Well, for your edification, you didn't score any points, since the readers here get all uppity about what's in the articles, so they have shown a propensity to care, even if you're just here to pass the time, or lie your yapper off for the convenient line it provides you for this momment.
Usually, the last stab of the sinking pirate goes something it like: " It doesn't matter !"
Then Davey Jones proves to 'em it does.
-
Nice try, but the worst problem for you is, it matters so much to you, you think I'm not me. NOW THAT's FUNNY !
ahhahahahaaha
ClownPuncher - Wednesday, September 30, 2009 - link
Aspbergers.Kaleid - Wednesday, September 30, 2009 - link
No, most people with Asperger's are highly functional. This is something else.Finally - Thursday, October 1, 2009 - link
It's Rain Man?tamalero - Friday, October 2, 2009 - link
its assburgers, google it.redpriest_ - Wednesday, September 30, 2009 - link
I can't help but note for the record that um, the card isn't out yet, so how can they win when no one knows when you can actually buy one yet? And for the record, I have a 5870 in my system, right now, that can play games....right now. I went to a retail store and bought it. That's how simple it was. I know you've been posting tons of FUD in the other review forums about how it's unavailable etc etc but the fact is, it IS available, and multiple people can own one.Also, let me state for the record that I have owned nvidia GPUs in the past so that I'm vendor agnostic. I buy whatever solution is available and better. KEY POINTS: AVAILABLE. BETTER.
SiliconDoc - Thursday, October 1, 2009 - link
Here's how they can win, here the NVidia master holds FERMI up for all to see !http://www.fudzilla.com/content/view/15762/1/">http://www.fudzilla.com/content/view/15762/1/
Aww, dat too bad for the wittle wed woosters. It really is real, little red lying hoods.