NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
Architecting Fermi: More Than 2x GT200
NVIDIA keeps referring to Fermi as a brand new architecture, while calling GT200 (and RV870) bigger versions of their predecessors with a few added features. Marginalizing the efforts required to build any multi-billion transistor chip is just silly, to an extent all of these GPUs have been significantly redesigned.
At a high level, Fermi doesn't look much different than a bigger GT200. NVIDIA is committed to its scalar architecture for the foreseeable future. In fact, its one op per clock per core philosophy comes from a basic desire to execute single threaded programs as quickly as possible. Remember, these are compute and graphics chips. NVIDIA sees no benefit in building a 16-wide or 5-wide core as the basis of its architectures, although we may see a bit more flexibility at the core level in the future.
Despite the similarities, large parts of the architecture have evolved. The redesign happened at low as the core level. NVIDIA used to call these SPs (Streaming Processors), now they call them CUDA Cores, I’m going to call them cores.
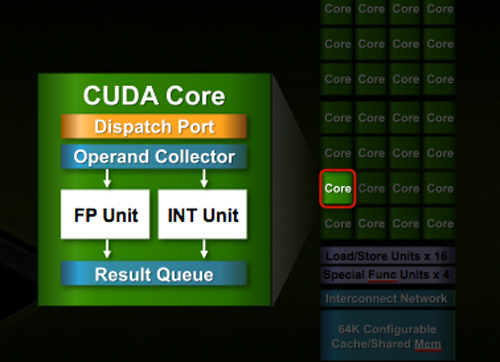
All of the processing done at the core level is now to IEEE spec. That’s IEEE-754 2008 for floating point math (same as RV870/5870) and full 32-bit for integers. In the past 32-bit integer multiplies had to be emulated, the hardware could only do 24-bit integer muls. That silliness is now gone. Fused Multiply Add is also included. The goal was to avoid doing any cheesy tricks to implement math. Everything should be industry standards compliant and give you the results that you’d expect.
Double precision floating point (FP64) performance is improved tremendously. Peak 64-bit FP execution rate is now 1/2 of 32-bit FP, it used to be 1/8 (AMD's is 1/5). Wow.
NVIDIA isn’t disclosing clock speeds yet, so we don’t know exactly what that rate is yet.
In G80 and GT200 NVIDIA grouped eight cores into what it called an SM. With Fermi, you get 32 cores per SM.
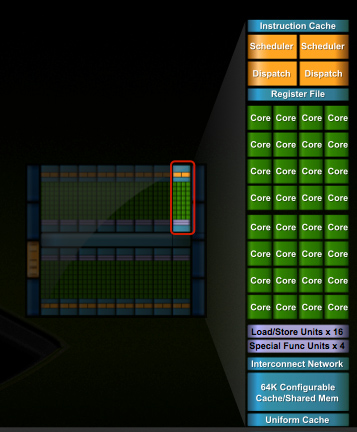
The high end single-GPU Fermi configuration will have 16 SMs. That’s fewer SMs than GT200, but more cores. 512 to be exact. Fermi has more than twice the core count of the GeForce GTX 285.
| Fermi | GT200 | G80 | |
| Cores | 512 | 240 | 128 |
| Memory Interface | 384-bit GDDR5 | 512-bit GDDR3 | 384-bit GDDR3 |
In addition to the cores, each SM has a Special Function Unit (SFU) used for transcendental math and interpolation. In GT200 this SFU had two pipelines, in Fermi it has four. While NVIDIA increased general math horsepower by 4x per SM, SFU resources only doubled.
The infamous missing MUL has been pulled out of the SFU, we shouldn’t have to quote peak single and dual-issue arithmetic rates any longer for NVIDIA GPUs.
NVIDIA organizes these SMs into TPCs, but the exact hierarchy isn’t being disclosed today. With the launch's Tesla focus we also don't know specific on ROPs, texture filtering or anything else related to 3D graphics. Boo.
A Real Cache Hierarchy
Each SM in GT200 had 16KB of shared memory that could be used by all of the cores. This wasn’t a cache, but rather software managed memory. The application would have to knowingly move data in and out of it. The benefit here is predictability, you always know if something is in shared memory because you put it there. The downside is it doesn’t work so well if the application isn’t very predictable.
Branch heavy applications and many of the general purpose compute applications that NVIDIA is going after need a real cache. So with Fermi at 40nm, NVIDIA gave them a real cache.
Attached to each SM is 64KB of configurable memory. It can be partitioned as 16KB/48KB or 48KB/16KB; one partition is shared memory, the other partition is an L1 cache. The 16KB minimum partition means that applications written for GT200 that require 16KB of shared memory will still work just fine on Fermi. If your app prefers shared memory, it gets 3x the space in Fermi. If your application could really benefit from a cache, Fermi now delivers that as well. GT200 did have an L1 texture cache (one per TPC), but the cache was mostly useless when the GPU ran in compute mode.

The entire chip shares a 768KB L2 cache. The result is a reduced penalty for doing an atomic memory op, Fermi is 5 - 20x faster here than GT200.








415 Comments
View All Comments
silverblue - Thursday, October 1, 2009 - link
Am I hearing you right - you say GT300 isn't a paper launch despite there being no cards for sale for the next few months, yet you said the 5870 was AND THERE WERE CARDS FOR SALE WHEN YOU MADE THE COMMENT! I don't care that you couldn't locate one, the simple fact is people had already bought cards from the first trickle (emphasis on the trickle part) and as such made your statement completely invalid.How much more rubbish are you going to spew from your hole?
(note: I needed to have caps above to make a salient point and not just because I felt like holding the shift key for no particular reason)
SiliconDoc - Thursday, October 1, 2009 - link
roflmao - If you're hearing anything right, you'd keep your text yap shut.Please show me the LAUNCH information on GT300, there, brainless bubba, the liar. I really cannot imagine you are that stupid, but then again, it is possible.
Congratulations for being a COMPLETE IDIOT AND LIAR! Really, you must work very hard to maintain that level of ignorance. In fact, the requirement to be that stupid exceeds the likelihood that you actually are purely ignorant, and therefore, it is more likely you're a troll. My condolences in either case in all seriousness.
silverblue - Thursday, October 1, 2009 - link
The proposed launch is late November but even Fudzilla concede that any problems will delay this. The earliest we'll see a GT300 on the shelves is just under 2 months. There, that's information for you. I want nVidia to launch GT300 this year but we don't always get what we wish for.Where did I lie in any of my previous posts? Oh right... I didn't bow down to worship the Green God(dess). If you had any semblance of an open mind or any stability at all, your nose wouldn't need cleaning. Calling me a troll is pure comedy gold and offering me your pity is outstanding to say the least :)
Keep trying. Or don't. Either way, I doubt many people care for your viewpoints anymore.
SiliconDoc - Thursday, October 1, 2009 - link
Oh jeeze, one red rooster who finally gets it.Congratulations, you're not the dumbest of your crowd.
--
No shirking here comes the QUOTE !
" The proposed launch is late November " !!! whoo hoo !
Now a proposed launch is not an official launch- try to keep that straight in the gourd haters when the time comes.
--
Pass it along to all the screaming tards, won't you please, you talk their language, or perhapos we'll just say you already have, because, by golly, they can believe you.
ROFLMAO
rennya - Thursday, October 1, 2009 - link
'Nvidia LAUNCHED TODAY... se page two by your insane master Anand.'This what you have said yourself somewhere in this very discussion. So you must have known about this so-called launch yourself.
SiliconDoc - Thursday, October 1, 2009 - link
That's called sarcasm dear. Jiminy crickets.palladium - Thursday, October 1, 2009 - link
How can you tell if that's not a GTX285 with redesigned cover/cooler/PCB?samspqr - Monday, October 5, 2009 - link
it is SO funny that that thing silicondoc's master/god is holding in his hand ended up revealing itself as nothing more than a mock-up...SiliconDoc - Wednesday, September 30, 2009 - link
PS THE SILICON IS ALREADY CUT AND IN PRODUCTION!---
Yes anand at the bottom of page 1 claims "it's paper" - DECIEVING YOU, since the WAFERS HAVE ALREADY BEEN BURNED AND YIELDS ARE REPORTED HIGH ! (in spite of ati's marketing arm lying and claiming "only 9 cores per wafer yields" - A BIG FAT LIE NVIDIA POINTED OUT !
Where have you been with your head in the sand ?
--
So at the bottom of page 1 Anand leaves you dips with the impression "it's all paper" (but the TRUTH is DEVELOPER CARDS ARE ALREADY ASSEMBLED and being DEBUGGED and TESTED) just anand won't get one for 2 months.
---
THEN BY PAGE 2 ANAND CALLS IT A PAPER LAUNCH !
roflmao
Yes, the red rooster himself has convinced himself "today's nvidia LAUNCH" (that LAUNCH word is what anand made up in his deranged mind) is a paper launch "JUST LIKE ATI'S!".
---
It is nothing short of absolutely AMAZING.
The red rooster fan has boonswoggled his own gourd, stated in fasle terms, bashed it to be as bad as what ati just did with 5870, and IT'S NOT EVEN A LAUNCH DAY FOR NVIDIA !
---
Congratulations, the massive bias is SCREAMING off the page. LOL
It's hilarious, to say the least, that the master can be that deluded with his own spew!
gx80050 - Friday, October 2, 2009 - link
Die painfully okay? Prefearbly by getting crushed to death in a
garbage compactor, by getting your face cut to ribbons with a
pocketknife, your head cracked open with a baseball bat, your stomach
sliced open and your entrails spilled out, and your eyeballs ripped
out of their sockets. Fucking bitch
I would love to kick you hard in the face, breaking it. Then I'd cut
your stomach open with a chainsaw, exposing your intestines. Then I'd
cut your windpipe in two with a boxcutter.
Hopefully you'll get what's coming to you. Fucking bitch
I really hope that you get curb-stomped. It'd be hilarious to see you
begging for help, and then someone stomps on the back of your head,
leaving you to die in horrible, agonizing pain. Faggot
Shut the fuck up f aggot, before you get your face bashed in and cut
to ribbons, and your throat slit.