Original Link: https://www.anandtech.com/show/2240
Supermicro's Twin: Two nodes and 16 cores in 1U
by Johan De Gelas on May 28, 2007 12:01 AM EST- Posted in
- IT Computing
Introduction
There is something very intriguing about the server market. To understand it, you must take a look at the latest Gartner numbers and know a bit of background about Supermicro. Supermicro is the odd man out. Browsing through the website, you find very few trendy buzzwords; just the good old-fashioned "cutting edge technology" and "reliability". What happened to "SOA", "IT governance" and "IT lifecycle" to unearth "business value"? Surely a company that doesn't use "viral marketing", a massive amount of marketing blogs, and isn't present in "Second life" is close to extinction, right?
Supermicro is actually doing very well. In terms of annual growth it is one of the most successful companies. Supermicro is one of the rare companies where "marketing visionaries" have not taken over, and where engineers are still calling the shots: at the top of the company we find an engineer in heart and soul, Charles Liang. When we talk to HP, Dell, and IBM, they rarely consider Supermicro a competitor. Sun, HP, Dell, and IBM see each other as the biggest rivals, and depending who you talk to, Fujitsu-Siemens will be or will not be added to the small list of Tier-1 OEMs. Now take a look at the table below and consider that Supermicro ships about 600,000 servers a year.
| Server Market Share | |||||
| Company | 2006 Shipments | 2006 Market Share (%) | 2005 Shipments | 2005 Market Share (%) | 2006-2005 Growth (%) |
| Hewlett-Packard | 2,261,074 | 27.5 | 2,093,412 | 27.7 | 8 |
| Dell Inc. | 1,783,445 | 21.7 | 1,701,932 | 22.5 | 4.8 |
| IBM | 1,293,825 | 15.7 | 1,200,143 | 15.9 | 7.8 |
| Sun Microsystems | 368,603 | 4.5 | 342,457 | 4.5 | 7.6 |
| Fujitsu/Fujitsu Siemens | 256,794 | 3.1 | 262,898 | 3.5 | -2.3 |
| Other Vendors | 2,270,036 | 27.6 | 1,959,258 | 25.9 | 15.9 |
| Total | 8,233,777 | 100.0 | 7,560,100 | 100.0 | 8.9 |
Source: Gartner Dataquest (February 2007)
Indeed, if you look at a typical Gartner table, Supermicro is nowhere to be found, despite the fact that Supermicro sells about as many servers as Sun and Fujitsu-Siemens combined and has about 7 to 8% of the total server market. The market share of Supermicro - along with Tyan, Rackable Systems, MSI, ASUS and many others - can be found in the hodge-podge "other vendors" figure, which is also referred to (with a slightly less serious almost negative undertone) the "unbranded or white box" market.So why are companies like Supermicro absent in the big server market overviews? The answer lies of course in the financial side of things. The server revenue of IBM or HP is about 40-50 times higher than that of Supermicro. But that hardly matter for our readers: if Supermicro sells 8% of the total servers sold and the white box market is good for about a quarter of the volume of the server market, we have to ask an interesting question: what advantages does buying only from the Tier-1 OEMs bring you, and are there attractive alternatives in the white box market? We'll give them all a fair chance, as we are working with Tyan, Supermicro, MSI, HP, IBM, and others.
This server report is the first in a planned series of articles which will concentrate on the server and storage needs of SMBs. We find this to be a particularly interesting segment, as that is exactly where most of our readers come from: smaller and medium enterprises where the cost of hardware and software still matters; where the decision is still highly influenced by technical and price/performance considerations. We will search for the real tangible advantages that certain vendors and products can offer, advantages that really offer added value and lower TCO. To do so, we will keep an eye on TCO and we are working with several SMB which develop highly specialized server applications. This will allow us to give you some real world benchmarks of applications where performance still matters, a very good addition to our normal industry standard benchmarks.
In this first article, we look at a quite unique product of Supermicro: the Supermicro Twin, also known under its less sexy name Superserver 6015T-INF. We also introduce you to a first example of our new way of benchmarking servers.
Twin Server: Concept
The big idea behind the Twin Server is that Supermicro puts two nodes in a 1U pizza box. The first advantage is that processing power density is at least twice as high as a typical 1U, and even higher than many (much more expensive) blade systems.

TCO should also be further lowered by powering both nodes from the same 900W "more than 90% efficient" power supply.

Powering two nodes, the PSU should work at a load where it is close to its maximum efficiency. The disadvantage is that the PSU is a single point of failure. Nevertheless, the concept behind the Supermicro Twin should result in superior processing power density and performance/Watt, making it very attractive as a HPC cluster node, web server, or rendering node.
That is not all; the chassis is priced very competitively. We did a quick comparison with the Dell PowerEdge. As Supermicro's big selling point is the flexibility it offers to its customers in customizing the server's configuration, it is clear that Dell is probably the most dangerous Tier-1 opponent with its extremely optimized supply chain, direct sales model, and relatively customizable systems.
| Server Price Comparison | |||
| Components | Supermicro Twin (May 2007) | Components | Dell PowerEdge 1950 (May 2007) |
| 6015-T Chassis | $1,550 | Chassis | $3,610 |
| 2x Xeon 5320 | $1,000 | 1x Xeon 5320 | |
| 4x 2GB FB-DIMM | $1,480 | 4x 1GB FB-DIMM | |
| 4x Seagate ST3250820NS 250GB SATA NL35 | $340 | 2x 250GB SATA NL35 | |
| $4,370 | $3610 | ||
| 2x Xeon 5320 | $1,000 | 1x Xeon 5320 | $850 |
| Subtotal | $5,370 | Subtotal | $4,460 |
| Dell Discount | ($1,400) | ||
| Subtotal after discount | $3,060 | ||
| Total 2 systems: | $5,370 | Total 2 systems: | $6,120 |
While the difference isn't enormous, it is important to note that the Dell PowerEdge is one of the most aggressively priced servers out there, thanks to the huge discount. The idea behind the server is very attractive and the price is extremely competitive; these are reasons enough to see if the Supermicro Twin 1U can deliver in practice too. But first, we'll take a look at the technical features of this server.
Supermicro 6015T-T/6015T-INF Server
Two models exist : the 6015T-INF and the 6015T-T. The only difference is that the former has an additional InfiniBand connector. Supermicro sent us the 6015T-INF. The Superserver 6015T-INF consists of two Supermicro X7DBT-INF dual processor server boards. Each board is based on Intel's 5000P chipset and support two Intel 53xx/51xx/50xx series processors. Let's take a look at the scheme below.
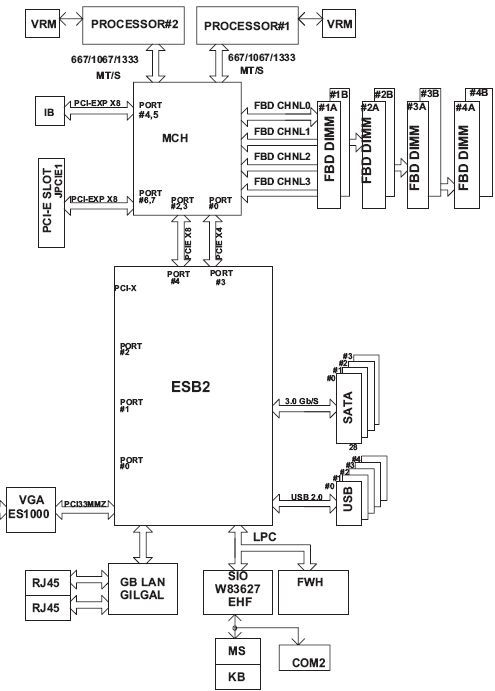
The Intel 5000p chipset has two I/O units, one with two x8 PCIe lanes and a second one with an x8 + x4 PCIe lane configuration. The first PCIe x8 connection of the first I/O unit is used to attach the 20 Gbit/s InfiniBand connection to the Northbridge (MCH). PCIe x8 offers 2 GB/s full duplex, which roughly matches the peak data bandwidth of the InfiniBand connection. InfiniBand is a point-to-point bidirectional serial interconnect, but that probably doesn't say much. To simplify we could describe it as a technology similar to PCI Express, but one that can also be used externally as a network technology like Ethernet - with the difference that this switched networking technology:
- offers more than 10 times the bandwidth of Gigabit Ethernet (1500 MB/s vs. 125 MB/s)
- 15 to 40 times lower latency than Gigabit Ethernet (2.25 µs vs. 100 µs)
- at a ten times lower CPU load (5% versus 50%)
Latency sensitive cluster applications that exchange a lot of (synchronizing) data between the nodes are a prime example of where one should use InfiniBand. A good example is Fluent, a Computational Fluid Dynamics (CFD) package. This article, written by Gilad Shainer, a senior technical marketing manager at Mellanox, shows how using low latency InfiniBand offers much better scaling over multiple nodes than Gigabit Ethernet.
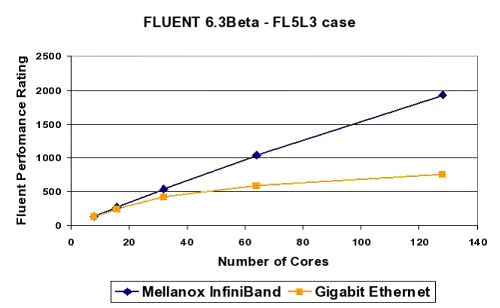
As you can see, with more than 32 cores (or 16 dual core Woodcrest CPUs), Gigabit Ethernet severely limits the performance scaling.
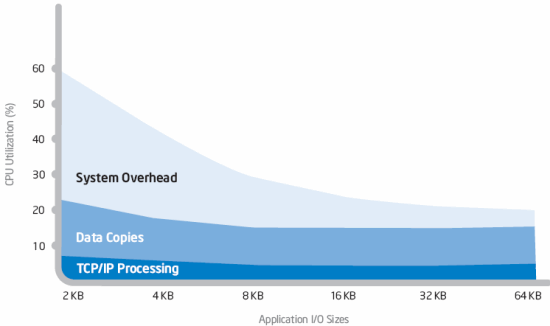
The second PCIe x8 is used as a PCIe slot. PCI-X is not an option due to the limited space available on each X7DB motherboard. So that is one of the limitations of the Twin: there is only one PCIe expansion slot available, which can contain a 2U height card. The PCIe x8 of the second I/O port offers Intel I/O Acceleration Technology (IOAT) to the dual Gigabit Controller. TCP/IP processing is only a small part of the CPU load that is a result of intensive networking activity. Especially with small data blocks, handling the interrupts and signals consumes many more cycles than pure TCP/IP processing.
The X7DBT has eight 240-pin DIMM sockets that can support up to 32 GB of ECC FBD (Fully Buffered DIMM) DDR2-667/533 SDRAM and support memory spares.
All memory modules used to populate the system should be the same size, type and speed.

Each board has four SATA connectors, but only two of them are connected to the storage backplane. That means that in reality, you are limited to two SATA disks per node. This is not a real limitation as this server is not intended to be a fileserver or database server. For a front end or HPC cluster node, two SATA disks in RAID-1 should be sufficient.

As you can see, expansion is limited to one half height PCIe card. A result of fitting two nodes in a 1U server.
Words of thanks
A lot of people gave us assistance with this project, and we would like to give them our sincere thanks.
Angela Rosario, Supermicro US
Michael Kalodrich, Supermicro US
(www.supermicro.com)
Jerry L. Baugh, Intel US
William H. Lea , Intel US
Matty Bakkeren, Intel Netherlands
(www.intel.com)
Marcel Eeckhout, MCS
Johan Van Dijck, MCS
(www.mcs.be)

Hopefully, Liz will still smile when we start our Oracle clustering research...
APUS Research team:
Elisabeth van Dijck, Oracle installation and fine tuning, MCS benchmarking
Tom Glorieux, Server & network administration
APUS software team:
Brecht Kets, Lead developer
Ben Motmans, Core developer
Leandro Cavalieri, Unix & power monitoring
Dieter Vandroemme, APUS benchmarking developer

The APUS software team: Dieter, Leandro, and Brecht
Benchmark configuration
Unfortunately, it is not that easy to get four CPUs of the same kind in the lab. We could only populate all four sockets with the Xeon E5320 (quad core 1.86 GHz). In the following pages you can read a more detailed description of our benchmarking methods.
Hardware configurations
Here is the list of the different configurations. The quad Opteron HP DL585 is only used as a reference point; this article is in no way meant to be an up-to-date AMD versus Intel comparison. Our focus is on the possibilities of the Twin 1U.
Xeon Server 1: Supermicro Superserver 6015T-INF
1 node, Dual Xeon DC 5160 3 GHz, Dual Xeon QC 2.33 GHz
2 nodes, 2 x 2 Xeon QC E5320
Intel 5000P chipset
Supermicro's X7DBT
(2 times) 4GB (4x1024 MB) Micron FB-DIMM Registered DDR-II 533 MHz CAS 4, ECC enabled
NIC: Dual Port Intel 82563EB Gigabit Platform LAN Connect
2 Seagate NL35 Nearline 250GB SATA-II 16MB 7200RPM
Xeon Server 2: Dual Xeon DP Supermicro Superserver 6015b-8+
Dual Xeon DP 5160 3 GHz
Intel 5000P chipset
Supermicro's X7DBR-8+
8 GB (8x1024 MB) Micron FB-DIMM Registered DDR-II 533 MHz CAS 4, ECC enabled
NIC: Dual Intel PRO/1000 Server NIC
2 Fujitsu MAX3073NC 73 GB - 15000 rpm - SCSI 320 MB/s
Opteron Server 1: Quad Opteron HP DL585
Quad Opteron 880 2.4 GHz
AMD8000 Chipset
16 GB (16x1048 MB) Crucial DDR333 CAS 2.5, ECC enabled
NIC: NC7782 Dual PCI-X Gigabit
2 Fujitsu MAX3073NC 73 GB - 15000 rpm - SCSI 320 MB/s
Client Configuration: Dual Opteron 850
MSI K8T Master1-FAR
4x512 MB Infineon PC2700 Registered, ECC
NIC: Broadcom 5705
Software
MS Windows Server 2003 Enterprise Edition, Service Pack 2
MCS eFMS WebPortal v9.2.43
3DS Max 9.0
APUS: a new way of benchmarking
Using industry benchmarks and full disclosure of testing methods is important, as it allows other people to verify your numbers. Therefore we have included a benchmark that everyone can verify (3DS Max architecture rendering). However, testing with real heavy duty applications is so much more interesting. These are the applications that are running in the datacenters, not SPECjbb or TPC. People really care about the performance, as when the applications start to crawl, it affects their work and business. Therefore, let me introduce you to our completely new way of benchmarking with our unique software, called APUS.
As many of our loyal readers know, quite a few of the IT-based articles are based on a close collaboration with the server lab of the College University of West-Flanders. While the academic server research is beyond the scope of this article, the main advantage is that we get the opportunity to work with IT firms which develop rather interesting server applications.
Of course testing these applications is rather complex: how can you recreate the most intensive parts of the real world use of an application and get at the same time a very repeatable and reliable real world benchmark? The answer lies in software developed at the same university called APUS. APUS (or Application Unique Stress-testing) allows us to use the logs of real world applications and turn them into a repeatable benchmark. The application is able to read the logs of almost every popular relational Database (DB2, Oracle, Sybase, MySQL, SQL server, PostGreSQL...) and web applications out there.
We are also working on "special protocols" so we can also use this benchmarking method for other socket applications. A highly tuned threading system allows us to simulate a few thousand users (and more) on one dual core portable. Complex setups with tens of clients are not necessary at all.
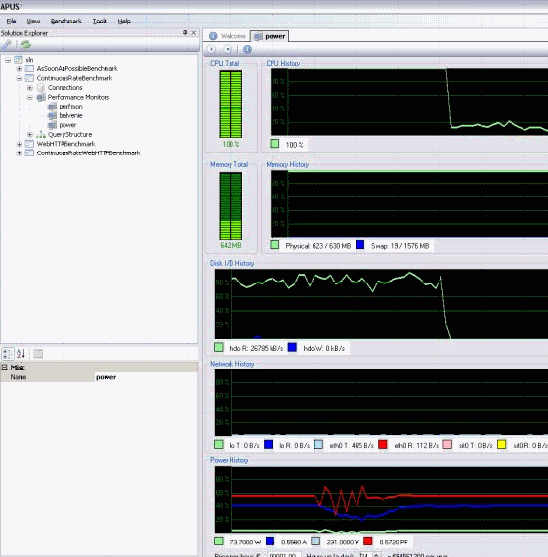
There is more: thanks to the hard work of Leandro, Ben, Brecht, and Dieter, APUS is much more than the typical stress tests you can find all over the web. It integrates:
- the monitoring of many important client parameters
- and server parameters
- performance measurements
- and is able to capture the corresponding power consumption in real time, making use of the EXTECH 380801
You may expect us to test with several real world applications in the future, but for now, let me introduce you to our first "as real world as it can get" application: MCS eFMS.
MCS eFMS software suite
One of the very interesting and more processing intensive applications that we encountered was developed by MCS. The MCS Enterprise Facility Management Solutions (MCS eFMS) is a state-of-the-art Facility Management Information System (FMIS). It includes applications such as space management (buildings), asset management (furniture, IT equipment, etc.), helpdesk, cable management, maintenance, meeting room reservations, financial management, reporting, and many more. MCS eFMS stores all information in a central Oracle database.
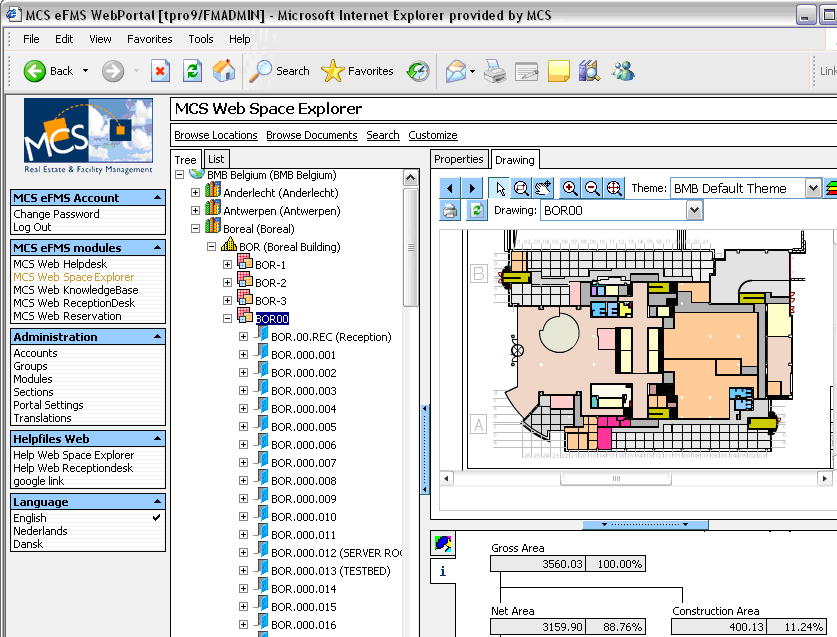 |
| MCS eFMS integrates space management, meeting room reservations and much more Click to enlarge |
What makes the application interesting to us as IT researchers is the integration of three key technologies:
- A web-based front end (IIS + PHP)
- Integrated CAD drawings
- Gets its information from a rather complex, ERP-like Oracle database.
It uses the following software:
- Microsoft IIS 6.0 (Windows 2003 Server Standard Edition R2)
- PHP 4.4.0
- FastCGI
- Oracle 9.2
The client, database server, and web server are connected via the same D-link Gigabit Switch. All cable connections worked at 1 Gbit/s full duplex
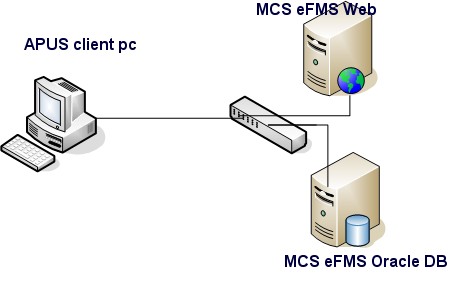
The only difference is that the hundreds of simulated users access the web server over one Gigabit Ethernet connection, while in the real world people access the MCS web applications over internal LANs as well over different WAN connections. As some of the pages easily take 400 to 800 ms (and higher under heavy load!) between receiving and sending the request, the few milliseconds that a good internet connection adds will not be significant.
MCS received a detailed and accurate model of how the web server and the clients react under different loads, large user groups or heavy pages, which enables them to optimize the MCS eFMS suite even more. Let us see the most interesting results of that report.
Network Load Balancing
It is pretty clear that we can not test the Supermicro 1U Twin in a conventional manner. Testing one node alone doesn't make sense: who care if it is 1-2% faster or slower than a typical Intel 5000p chipset based server? So we decided to use Windows 2003 Network Load Balancing or software load balancing. NLB is used mostly for splitting the load of heavy web-based traffic over several servers to improve response times, throughput and more importantly, availability. Each node sends a heartbeat signal. If a host fails and stops emitting heartbeats, the other nodes will remove it from their NLB cluster information, and although a few seconds of network traffic will be lost, the website remains available. What is even better is the fact that NLB, due to the relatively simple distributed filtering algorithm on each node, puts very little load on the CPUs of the node. The heartbeat messages also consume very little bandwidth. Testing with a fast Ethernet switch instead of our usual Gigabit Ethernet switch didn't result in any significant performance loss, whether we talk about response time (ms) or throughput (URLs served per second).
With four and up to eight CPUs per node, it takes a while before the NLB cluster becomes fully loaded, as you can see at the picture below.

Web server measurements are a little harder to interpret than other tests, as you always have two measurements: response time and throughput. Theoretically, you could set a "still acceptable" maximum response time and measure how many requests the system can respond to without breaking this limit. However, in reality it is almost impossible to test this way, as we simulate a number of simultaneous users which send requests and then measure both response time and throughput. Each simultaneous user takes about one second to send a new request. Notice that the number of simultaneous user is not equal to the total number of users. One hundred simultaneous users may well mean that there are 20 users constantly clicking to get new information while 240 others are clicking and typing every 3 seconds.
Another problem is of course that in reality you never want your web server to be at 100% CPU load. For our academic research, we track tens of different parameters, including CPU load. For a report such as this one, this would mean however that you have to wade through massive tables to get an idea how the different systems compare. Therefore, we decide to pick out a request rate at which all systems where maxed out, to give an idea of the maximum throughput and the associated latency. In the graphics below, 200 simultaneous users torture the MCS web application requesting one URL every second.
The single node tests are represented by the lightly colored graphs, the darker graphs represent our measurement in NLB mode (2 nodes). We were only able to get four Xeon E5320 (quad core 1.86 GHz Intel Core architecture) processors for this article, unfortunately; it would have been nice to test with various other CPUs in 4-way configurations, but sometimes you have to take what you can get.
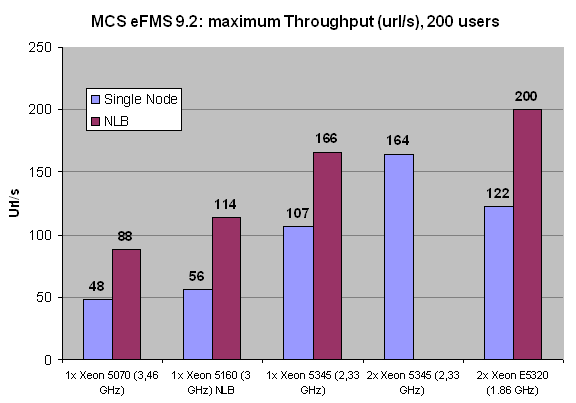
Notice that two CPUs connected by NLB and thus Gigabit Ethernet are not slower than two CPUs connected by the FSB. In other words, two nodes with one CPU per node are not slower than two CPUs in a single node. The most likely explanation is that the overhead of communicating over a TCP/IP Ethernet connection is offset by the higher amount of bandwidth that each CPU in the node has available. From the numbers above we may conclude that NLB scales very well: adding a second node increases the throughput by 60 to 100%. Scaling decreases as we increase the CPU power and the number of cores which is no surprise, as the latency of the Gigabit connection between the nodes starts to become more important. To obtain better scaling, we would probably have to use an InfiniBand connection but for this type of application that seems a bit like overkill.
Also note that 200 users means 200 simultaneous users which may translate - depending on the usage model of the client - to a few thousands of real active users in a day. The only configuration that can sustain this is the NLB configuration: in reality it could serve about 225 simultaneous users at one URL/s, but as we only asked for 200, it served up 200.
To understand this better, let us see what the corresponding response time is. Remember that this is not the typical response time of the application, but the response you get from an overloaded server. Only the 16 Xeon E5320 cores were capable of delivering more than 200 URL/s (about 225), while the other configurations had to work with a backlog.
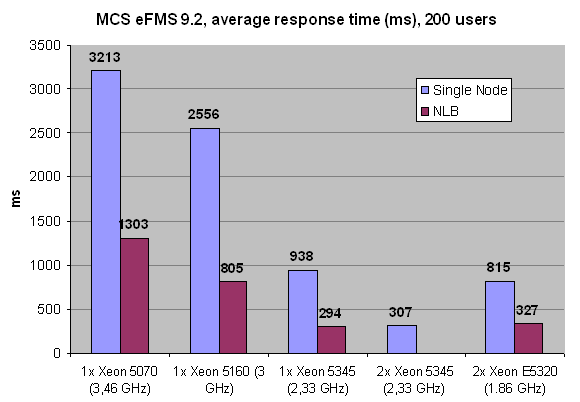
It is a bit extreme, but it gives a very good idea of what happens if you overload a server: response times increase almost exponentially. When we tested with 100 users, our dual Xeon E5320 (1.86 GHz, four cores in one node) provided a response time of about 120 ms on average per URL - measured across about 40 different URLs - and so did the same configuration in NLB (two nodes). A Xeon 5160 in each node in NLB responded in 145 ms, as the demanded throughput was much closer to its maximum of 114 ms. Now take a look at the measured response times at 200 URL/s.
The Xeon Dempsey 5070 (dual core 3.46 GHz 2MB NetBurst architecture) is only capable of sustaining half the user requests we demand from it, and the result is a 10X higher response time than our two node 16 core NLB server, or almost 30X higher than the minimum response time. Our quad Xeon 1.86 in NLB was capable of a response time of 327 ms, almost 3X higher than the lowest measured response time at 100 URL/s. So we conclude that pushing a web server to 90% of its maximum will result in a ~3X higher response time. This clearly shows that you should size your web server to work at about 60%, and no peak should go beyond 90%. Overload your web server with twice the traffic it can handle, and you'll be "rewarded" with response times that get 30X higher than the minimum necessary response time.
3DSMax 9 Backburner Rendering
A Supermicro Twin 1U could also be used as part of a rendering farm. We tested with 3D Studio Max version 9, which has been improved to work better with multi-core systems (compared to version 7 and 8) . We used the "architecture" scene of the SPEC APC test (3DS Max 7), which has been our favorite benchmarking scene for years.
All tests are done with 3dsmax's default scanline renderer, SSE is enabled, and we render at HD 720p resolution. We measure the time it takes to render frames 20 to 29, exactly 10 frames. But this time we installed the "Backburn" server on each node. The Backburn server allows us to send our renderings via the network to each node. Both nodes are still connected via our Gigabit D-link DGS-1224T switch. Then we make use of "net render". Below you can see the Backburn server in action.
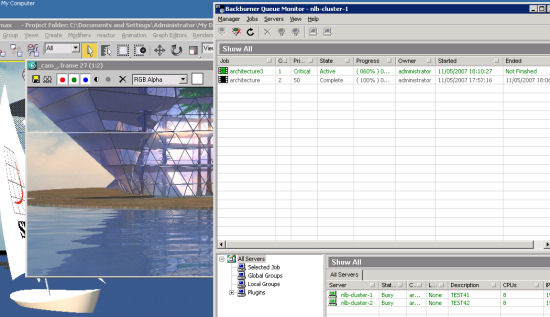
Notice how the first node renders the even frames. Below you can see how this looks on the 3DSMax client. The Backburn monitor gives us an overview of the current rendering. Also note that one node is acting as both a rendering node and a Backburner client.
That does not hamper performance however. "2N" means that Backburner used both nodes of the 1U twin. So the orange bar represents the 3dsmax performance we get from rendering at two nodes, with one dual core Xeon 5160 ("Woodcrest") in each node. In each node, one socket was not used. Dual Xeon 5160 3 GHz means that we only use one node with the two sockets occupied by Xeon 5160 CPUs.
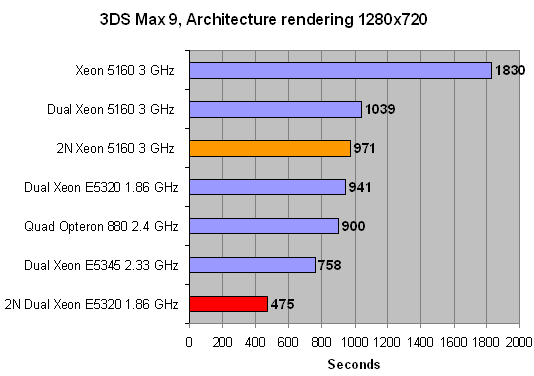
We notice a 98% speedup going from one node (941s) to a second node (475s). Of course, with only two nodes, the network overhead is minimal but this is superb scaling!
Also notice that two Xeons 5160 in one node is a little slower - about 6% - than one Xeon 5160 in each node. The mostly likely explanation is that the "setup" (before rendering) of the frame is adding overhead, as this process is not multithreaded. With two nodes, two frames are set up in parallel, using one core per node. Only two cores are idle at that time. On a single node, three cores are idle and only one core will be busy processing this pre-rendering code.
Electricity Bill
Having one PSU power two nodes should make sure that the 900W PSU is never working at a very low load, and thus at its lowest efficiency. Using motherboards with only the features that are really necessary and a PSU that is "more than 90%" efficient should also help. On the flipside, a 1U server with 16 cores is harder to cool than two 1U servers with 8 cores.

So how much power can you save with Supermicro's Twin compared to two 1U servers? We decided to find out with Supermicro's 1U 6015b-8+ server. This server has a slightly less efficient 700W PSU, "up to 85% efficient", which is still better than the average PSU in the 1U market. Also, the 6015b+8+ features a U320SCSI controller and one SCSI320 disk which adds about 10-15W.
We tested for 400 seconds (the x-axis).
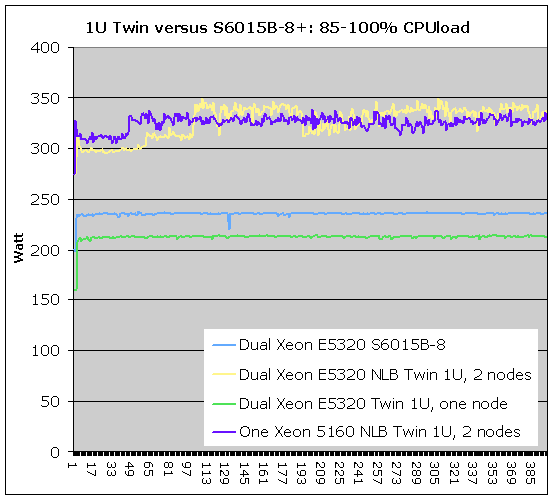
To sum up our findings:
- A 1U server with 85% efficient PSU needs +/- 230 W
- The Twin 1U server with 1 Node powered on needs +/- 213 W
- Twin 1U server with both nodes working uses +/- 330 W
- The second node adds only 55% more power
- In comparison with 2x 1U servers, we save about 130W or about 30% thanks to Twin 1U system
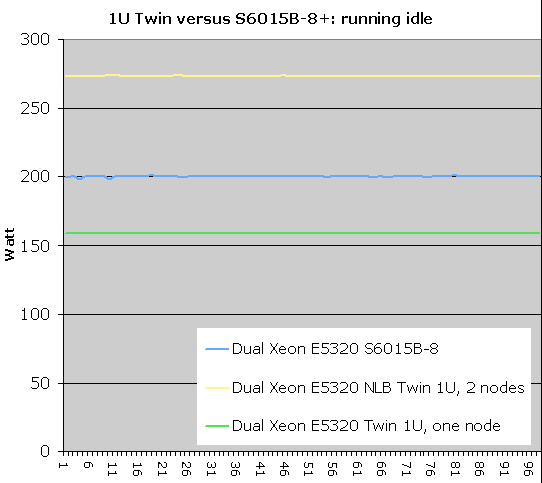
To get a better idea, we summarized the averages in the table below:
| Average Power Use | ||
| Configuration | Idle (Watt) | Full Load (Watt) |
| Twin 1U: 1 node | 160 | 213 |
| Twin 1U: 2 nodes | 271 | 330 |
| Power increase 1 to 2 node | 69% | 55% |
| Normal 1U | 200 | 230 |
| 2 x Normal 1U | 400 | 460 |
| Power savings compared to "Normal 1U" | 129 | 130 |
Even if we take into account that two "normal" 1U servers would probably consume a bit less (as it gets harder to keep them at 100% load), and even if we take into account the fact that the SCSI controller and disk increase the power consumption by about 10W, we think it is safe to say that each 1U Twin server saves about 100W compared to two "normal" 1U servers. Mission accomplished for the Supermicro PSU engineers.
Analysis
The Supermicro Twin 1U combined with Intel's latest quad core technology offers an amazing amount of processing power in a 1U box. Just a bit more than two years ago, four cores in a 1U server was not a common setup. Now we get four times as many cores in the same space. Even better is that the second node increases power requirements by only 55%, while a second server would probably double the power needed. Considering the very competitive price, we can conclude that the Supermicro 1U Twin is probably the most attractive offer on the market today for those looking for a HPC node or rendering farm node.
The situation is different for the other markets that Supermicro targets: "data center and high-availability applications". What makes the 1U Twin so irresistible for the HPC and rendering people resulted in a few shortcomings for the HA applications, for example the heavy duty web applications. Although there is little doubt in our mind that Supermicro has used a high-quality, high-efficiency power supply, the fact remains that it is a single point of failure that can take down both nodes. Of course, with a decent UPS protection, you can take away the number one killer of power supplies: power surges. And it must be said that several studies have shown that failing hardware causes only 10% of the total downtime. About 50% of that, or 5% in total, is the result of a failed PSU. With a high quality PSU and a UPS with power surge protection, that percentage will be much lower. So it will depend on your own situation whether this is a risk you are willing to take. More than a third of the downtime is caused by software problems, and another third is planned downtime for upgrades and similar tasks. Those are downtimes that the Supermicro Twin with its two nodes is capable of avoiding with software techniques such as NLB and other forms of clustering.
A lot of the SMBs we are working with are looking collocate their HA applications servers and would love to run two web (NLB) and database servers (clustered) in only 2U. Right now, those servers typically take 4U and 6U, and the Supermicro twin could reduce those collocation costs considerably.
The biggest shortcoming is one that can probably be easily resolved by Supermicro: the lack of an SAS controller. It is not the higher performance of SAS that makes us say that, but VMWare's lack of support for SATA drives and controllers. A few Supermicro Twin 1U together with a shared storage solution (FC SAN, iSCSI SAN) could be an ideal platform to virtualize: you could run a lot of virtual nodes on the different physical nodes which results in consolidation and thus cost reduction, and the physical nodes offer high availability. However, VMWare ESX server does not support SATA controllers very well, so booting from a SAN is then the only option, which increases the complexity of the setup. A SAS controller would allow users to boot from two mirrored disks.
A SAS controller and a redundant power supply would make the Supermicro Twin 1U close to perfect. But let's be fair: the Supermicro Server Twin 1U is an amazing product for its primary market. It's not every day that we meet a 16 core server which saves you 100W of power and cuts rack space collocation in half... all for a very competitive price. Also, two nodes each with eight cores will remain a very interesting solution for applications such as rendering farms even when the quad core Xeon MP ("Tigerton") and AMD's quad core Opteron ("Barcelona") arrive. The reason is that performance will be competitive and that the price of four socket quad core systems will almost certainly be quite high. The Supermicro Twin 1U is an interesting idea which has materialized in an excellent product.
Advantages:
- Cuts necessary rack space in half, superb computing density
- Very high performance/power ratio, simply superior power supply
- Highest performance/price ratio today
- Excellent track record of Supermicro
- No SAS controller (for now?)
- Hard to virtualize with ESX server
- Cold swap PSU






