NVIDIA's GeForce 8800 (G80): GPUs Re-architected for DirectX 10
by Anand Lal Shimpi & Derek Wilson on November 8, 2006 6:01 PM EST- Posted in
- GPUs
Digging deeper into the shader core
Many of the same patterns that lead designers of current hardware to their conclusions are still true today. For instance, pixels next to each other on the screen still tend to follow a very similar path through the hardware. This means that it still makes sense to process pixels in quads. As for changes, as hardware becomes more programmable, we are seeing a higher percentage of scalar data being used. In spite of the fact that much of the work done by graphics hardware is vector based, it becomes easier to schedule code if we are working with a bunch of parallel, independent, scalar processors. It is also more efficient to build separate units for texture addressing and filtering, and ATI has done this for quite some time now.
NVIDIA has finally decoupled the texture units from their shader hardware, enabling math and texturing to happen at the same time with no scheduling issues. They have also decided to implement their math hardware as a collection of scalar processors that can be used together to perform vector operations. NVIDIA calls the scalar processors Stream Processors (SPs), and they handle all the math performed in the shader core of G80.
It isn't surprising to see that NVIDIA's implementation of a unified shader is based on taking a pixel shader quad pipeline, and breaking up the vector units into 4 scalar units. Now, rather than 4 pixel quads, we see 16 SPs per "quad" or block of stream processors. Each block of 16 SPs shares 4 texture address units, 8 texture filter units, and an L1 cache.
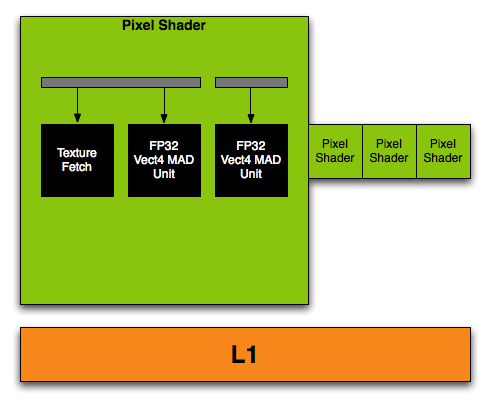
G70 Pixel Shader Quad
G80 Stream Processor Block
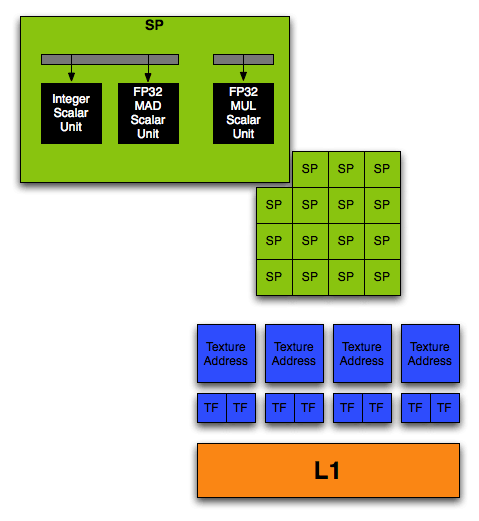
The fact that these SPs are now independent and scalar gives NVIDIA the ability to keep more of them busy more of the time. This is very important as programmers start to write longer more complex shaders. Even while working with vectors, programmers need to use scalar values all the time to manipulate and evaluate data.
Each Stream Processor is able to complete one MAD and one MUL per clock cycle. While this is based on maximum throughput, we can reasonably expect to achieve this even though the hardware is pipelined. In spite of the 4 or 5 cycles (depending on precision) latency of a MUL in Conroe, SSE is now capable of one MUL per cycle throughput (as long as there are no stalls in the pipeline). Latency of operations in G80 could be even longer and sustain high throughput, as most of the time we are working with code that isn't riddled with dependencies.
The fact that each SP is capable of IEEE 754 single precision and can sustain high throughput for MAD and MUL operations while running any type of shader code makes this hardware very powerful and more general purpose than ever.
As a thread exits the SP, G80 is capable of writing the output of the shader to memory. The fact that SPs can do this at any time (except after pixel shaders) goes beyond the DX10 spec of just allowing for stream output after the Geometry Shader. On previous hardware, data would have to go through every stage of the pipeline until a value was finally written out to the frame buffer. Now, we can write data out at the end of anything but a pixel shader (as pixel shaders must send their output straight over to the ROPs for processing). This will be a great benefit to GPGPU (general purpose computing on graphics processing units).








111 Comments
View All Comments
Nightmare225 - Sunday, November 26, 2006 - link
Are the FPS posted in this article, Minimum FPS, Average FPS, or Maximum? Thanks!multiblitz - Monday, November 20, 2006 - link
I enjoyed your reviews always a lot as they inclueded the video-capbilities for a HTPC on previous cards. Unfortunately this was this time not the case. Hopefully there will be a 2. Part covering this as well ? If so, it would be nice to make a compariosn on picture quality as well against the filters of ffdshow, as nvidia is now as well supporting postprocessing filters...DerekWilson - Tuesday, November 21, 2006 - link
What we know right now is that 8800 gets a 128 out of 130 on HQV tests.We haven't quite put together an HTPC look at 8800, but this is a possibility for the future.
epsil0n - Sunday, November 19, 2006 - link
I am not agree with this:"It isn't surprising to see that NVIDIA's implementation of a unified shader is based on taking a pixel shader quad pipeline, and breaking up the vector units into 4 scalar units. Now, rather than 4 pixel quads, we see 16 SPs per "quad" or block of stream processors. Each block of 16 SPs shares 4 texture address units, 8 texture filter units, and an L1 cache."
If i understood well this sentence tells that given 4 pixels the numbers of SPs involved in the computation are 16. Then, this assumes that each component of the pixel shader is computed horizontally over 16 SP (4pixel x 4rgba = 16SP). But, are you sure??
I didn't found others articles over the web that speculate about this. Reading others articles the main idea that i realized is that a shader is computed by one and only one SP. Each vector instruction (inside the shader) is "mapped" as a sequence of scalar operations (a dot product beetwen two vectors is mapped as 4 MUD/ADD operations). As a consequence, in this scenario 4 pixels are computed only by 4 SPs.
DerekWilson - Tuesday, November 21, 2006 - link
Honestly, NVIDIA wouldn't give us this level of detail. We certainly pressed them about how vertices and pixels map to SPs, but the answer we got was always something about how dynamic the hardware is able to dynamically schedule the SPs optimally according to what needs to be done.They can get away with being obscure about how they actually process the data because it could happen either way and provide the same effect to the developer and gamer alike.
Scheduling the simultaneous processing one vec4 MAD operation on 4 quads (16 pixels) over 4 groups of 4 SPs will take 4 clock cycles (in terms of throughput). Processing the same 16 pixels on 16 SPs will also take 4 clock cycles.
But there are reasons to believe that things happen the way we described. Loading components of 16 different "threads" (verts, pixels or whatever) would likely be harder on the cache than loading all 4 components of 4 different threads. We could see them schedule multiple ops from 4 threads to fill up each block of shaders -- like computing 4 consecutive scalar operations for 4 threads on 16 SPs.
At the same time, it might be easier to maximize SP utilization if 16 threads were processed on one block of SPs every clock.
I think the answer to this question is that NVIDIA knows, they didn't tell us, and all we can do is give it our best guess.
xtknight - Thursday, November 16, 2006 - link
This has been AT's best article in awhile. Tons of great, concise info.I have a question about the gamma corrected AA. This would be detrimental if you've already calibrated your display, correct (assuming the game heeds to the calibration)? Do you know what gamma correction factor the cards use for 'gamma corrected AA'?
DerekWilson - Monday, November 20, 2006 - link
I don't know if they dynamically adjust gamma correction based on monitor (that would be nice though) ...if they don't they likely adjusted for a gamma of either (or between) 2.2 or 2.5.
Also, thanks :-) There was a lot more we wanted to pack in, but I'm glad to see that we did a good job with what we were able to include.
Thanks,
Derek Wilson
bjacobson - Sunday, November 12, 2006 - link
This comment is unrelated, but could you implement some system where after rating a comment, on reload the page goes back to the comment I was just at? Otherwise I rate something halfway down and then have to spend several seconds finding where I just was. Just a little nuissance.Thanks for the great article, fun read.
neo229 - Friday, November 10, 2006 - link
This is a very suspect quote. A card that requires two PCIe power connectors is going to dissipate a lot of heat. More heat means there must be a faster, louder fan or more substantial and costly heat sink. The extra costs associated with providing a truly quiet card mean that the bulk of manufacturers go with the loud fan option.
DerekWilson - Friday, November 10, 2006 - link
If manufacturers go with the NVIDIA reference design, then we will see a nice large heatsink with a huge quiet fan.Really, it does move a lot of air without making a lot of noise ... Are there any devices we can get to measure the airflow of a cooling solution?
We are also seeing some designs using water cooling and theres even one with a thermo-electric (peltier) cooler on it. Manufacturers are going to great lengths to keep this thing running cool without generating much noise.
None of the 8 retail cards we are testing right now generate nearly the noise of the X1950 XTX ... We are working on a retail roundup right now, and we'll absolutely have noise numbers for all of these cards at load.