Intel's 45nm Dual-Core E8500: The Best Just Got Better
by Kris Boughton on March 5, 2008 3:00 AM EST- Posted in
- CPUs
Determining a Processor Warranty Period
Like most electrical parts, a CPU's design lifetime is often measured in hours, or more specifically the product's mean time to failure (MTTF), which is simply the reciprocal of the failure rate. Failure rate can be defined as the frequency at which a system or component fails over time. A lower failure rate, or conversely a higher MTTF, suggests the product on average will continue to function for a longer time before experiencing a problem that either limits its useful application or altogether prevents further use. In the semiconductor industry, MTTF is often used in place of mean time between failures (MTBF), a common method of conveying product reliability with hard drive. MTBF suggests the item is capable of repair following failure, which is often not the case when it comes to discrete electrical components such as CPUs.
A particular processor product line's continuous failure rate, as modeled over time, is largely a function of operating temperature - that is, elevated operating temperatures lead to decreased product lifetimes. Which means, for a given target product lifetime, it is possible to derive with a certain degree of confidence - after accounting for all the worst-case end-of-life minimum reliability margins - a maximum rated operating temperature that produces no more than the acceptable number of product failures over a period of time. What's more, although none of Intel's processor lifetimes are expressly published, we can only assume the goal is somewhere near the three-year mark, which just so happens to correspond well with the three-year limited warranty provided to the original purchaser of any Intel boxed processor. (That last part was a joke; this is no accident.)
When it comes to semiconductors, there are three primary types of failures that can put an end to your CPU's life. The first, and probably the more well-known of the three, is called a hard failure, which can be said to have occurred whenever a single overstress incident can be identified as the primary root cause of the product's end of life. Examples of this type of failure would be the processor's exposure to an especially high core voltage, a recent period of operation at exceedingly elevated temperatures, or perhaps even a tragic ESD event. In any case, blame for the failure can be (or most often obviously should be) traced back and attributed to a known cause.
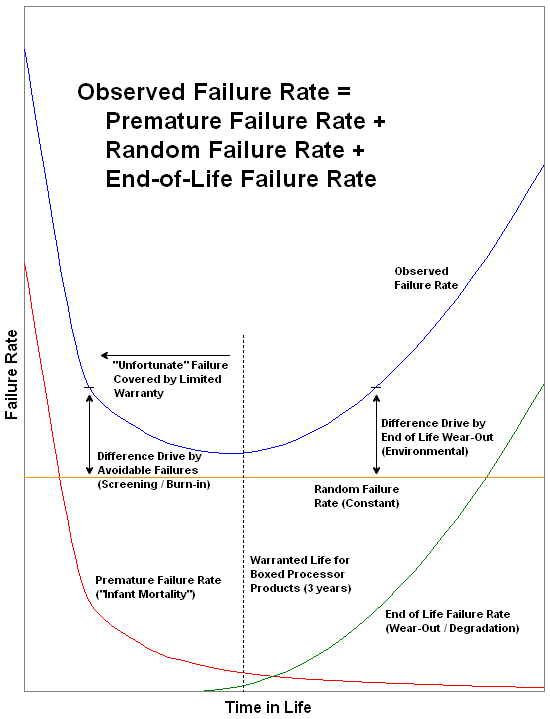
This is different from the second failure mode, known as a latent failure, in which a hidden defect or previously unnoted spot of damage from an earlier overstress event eventually brings about the component's untimely demise. These types of failure can lay dormant for many years, sometimes even for the life of the product, unless they are "coaxed" into existence. Several severity factors can be used to determine whether a latent failure will ultimately result in a complete system failure, one of those being the product's operating environment following the "injury." It is accepted that components subjected to a harsher operating environment will on average reach their end of life sooner than those not stressed nearly as hard. This particular failure mode is sometimes difficult to identify as without the proper post-mortem analysis it can be next to impossible to determine whether the product reached end-of-life due to a random failure or something more.
The third and final failure type, an early failure, is commonly referred to as "infant mortality". These failures occur soon after initial use, usually without any warning. What can be done about these seemingly unavoidable early failures? They are certainly not attributable to random failures, so by definition it should be possible to identify them and remove them via screening. One way to detect and remove these failures from the unit population is with a period of product testing known as "burn-in." Burn-in is the process by which the product is subjected to a battery of tests and periods of operation that sufficiently exercise the product to the point where these early failures can be caught prior to packaging for sale.
In the case of Intel CPUs, this process may even be conducted at elevated temperatures and voltages, known as "heat soaking." Once the product passes these initial inspections it is trustworthy enough to enter the market for continuous duty within rated specifications. Although this process can remove some of the weaker, more failure prone products from the retail pool - some of which might have very well gone on to lead a normal existence - the idea is that by identifying them earlier, fewer will come back as costly RMA requests. There's also the fact that large numbers of in-use failures can have a significant negative impact on the public perception of a company's ability to supply reliable products. Case in point: the mere mention of errata usually has most consumers up in arms before they are even aware of the applicability.
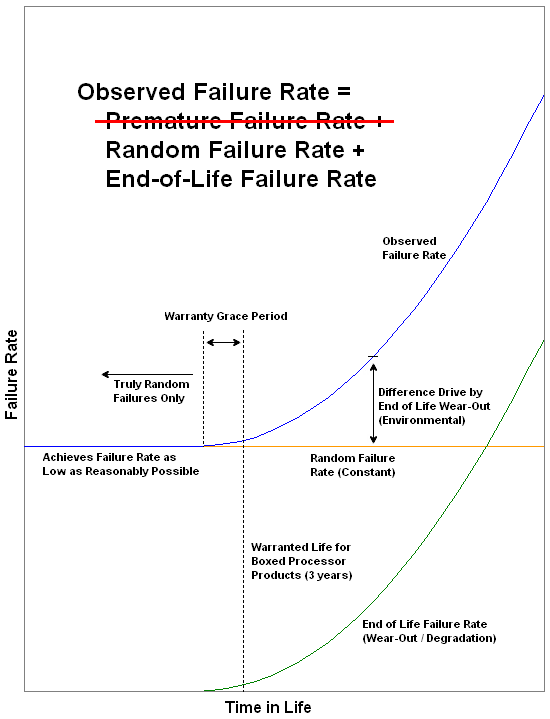
The graphic above illustrates how the observed failure rate is influenced by the removal of early failures. Because of this nearly every in-use failure can be credited as unavoidable and random in nature. By establishing environmental specifications and usage requirements that ensure near worry-free operation for the product's first three years of use, a "warranty grace period" can be offered. This removes all doubt as to whether the failure occurred because of a random event or the start of its eventual wear-out, where degradation starts to play a role in the observed failures.
Implementing process manufacturing, assembly, and testing advancements that lower the probability of random failures is a big part of improving any product's ultimate reliability rate. By carefully analyzing the operating characteristics of each new batch of processors, Intel is able to determine what works in achieving this goal and what doesn't. Changes that bring about significant improvements in product reliability - enough to offset the cost of a change to the manufacturing process - are sometimes implemented as a stepping change. The additional margin created by the change is often exploitable with respect to realizing greater overclocking potential. Let's discuss this further and see exactly what it means.








45 Comments
View All Comments
mdma35 - Friday, October 9, 2009 - link
Epic Article was pleasure to read thnx for sucj informative stuffjamstan - Sunday, July 13, 2008 - link
I just did a build with an E8500. The temp always shows 30 degrees no matter how high I overclock it or what speed I have my Vantec Tornado at. Being an overclocker it stinks that I bought a cpu with a temp sensor that doesn't work. I guess its a common problem with this cpu and I hear Intel won't RMA a cpu with a bad sensor. I'm gonna be giving them a call.Johnbear007 - Saturday, March 8, 2008 - link
I'd still like to know (other than microcenter) what retailer(S) are carrying the q6600 for "under 200$". I would much rather have a sub 200$ q6600 than a 260$ e8400 from mwaveMrSpadge - Thursday, March 6, 2008 - link
I do not agree with much of mindless1's critique on page 3, but we arrive at a somewhat similar conclusion: the section " The Truth About Processor "Degradation" " is lacking. Rather than adressing my issues with mindless1's post I'll just explain my point.Showing the influence of temperature on reliability is nice and well, but you neglect the factor which is by far the most important: voltage. It's effect on reliability / expected lifetime / MTTF is much higher than temperature (within sane limits).
How did you generate the curves in the first plot on that page? Is it just a guess or do you have exact data? Since you mention the 8500 specifically I can imagine that you got the data (or formula) from some insider. If so I'd be curious about how these curves look like if you apply e.g. 1.45 V. There should be a drastic reduction in lifetime.
If you don't think voltage is that important and you have no ways to adjust the calculations, you could pm dmens here at AT. I'd say he's expert enough in this field.
MrS
Toferman - Thursday, March 6, 2008 - link
Another great article, thanks for your work on this Kris. :)xkon - Thursday, March 6, 2008 - link
where are the sub $200 q6600's? i know microcenter had some for $200, but they are no where near me. any other ones? stating it in the article like that makes me think they are available at almost any retailer for that price. maybe if it was rephrased to something like they have been known to be priced as low as $200 or something like that. then again. maybe i'm not in the know, and am just not looking hard enough.TheJian - Thursday, March 6, 2008 - link
Yet another example of lies. The cheapest Q6600 on pricewatch is $243. And that doesn't come with a 3yr warranty OR a heatsink. So really the cheapest is $253 for retail box with heatsink/fan and 3yr. That's a FAR cry from $200. Cheapest on Cnet.com is $255. Where did they search to find these magical $200 Q6600 chips? I want one. I suspect pricegrabber etc would show the same. I'm too lazy to check now...LOLMaulSidious - Thursday, March 6, 2008 - link
dunno about america but in britain you can get a q6600 anywhere for 130-150 poundsJohnbear007 - Thursday, March 6, 2008 - link
150 pounds is about 250-300$ american which is nowhere near what the articles author is claiming. One microcenter deal doesnt really constitute claiming you can bag one from retailer(S) for under 200$. Also, another poster pointed to what he called a q6700 for 80$. That is not true, it was an e6700 which is dual core not quad.Karaktu - Wednesday, March 5, 2008 - link
I would just like to point out that it has been possible to run a sub-90-watt maximum HTPC for nearly two years. In fact, I've been doing it.It DOES require a Core Duo or Core 2 Duo mobile chip, but MoD isn't a new concept.
ASUS N4L-VM DH
- Using onboard Intel graphics, Realtek SPDIF and Gigabit network
Core Duo T2500 (2.0GHz)
- Cooled by a Nactua NC-U6 northbridge cooler and 60mm fan set to low
2 x 1GB DDR2 667
Vista View D1N1-E NTSC/ATSC PCI-E tuner
Vista View D1N1-I NTSC/ATSC PCI tuner
- (That's two analog and two HDTV tuners)
1TB WDC GP 5400rpm hard drive
750GB Samsung Spinpoint F1 7200rpm hard drive
Antec Fusion case (rev 1)
- VFD
- 430-watt 80 Plus power supply
- 2 x 120mm TriCool fans set to low
- External IR for remote and keyboard
Running MCE 2005
Idles at 68 watts AT THE WALL and draws a maximum of 90 watts at full load (recording 4 shows and watching a fifth show/movie).
If I ever get around to dropping the PSU to an EA-380, I'm sure the efficiency would go up a little since I would be closer to that magic 20 - 80% range on the power supply.
Joe