Westmere-EX: Intel's Flagship Benchmarked
by Johan De Gelas on May 19, 2011 1:30 PM EST- Posted in
- IT Computing
- Intel
- Xeon
- Cloud Computing
- Westmere-EX
Power Extremes: Idle and Full Load
Idle and full load power measurements are hardly relevant for virtualized environments but they offer some interesting datapoints. In the first test we report the power consumption running vApus Mark II, which means that the servers are working at 85-98% CPU load. We measured with four tiles, but we also tested the Xeon with five tiles (E7-4870 5T).
We test with redundant power supplies working, so the Dell R815 uses 1+1 1100W PSUs and the QSSC-4R uses 2+2 850W PSU. Remember that the QSSC server has cold redundant PSUs, so the redundant PSUs consume almost nothing. There's more to the story than just the PSU and performance, of course: the difference in RAS features, chassis options, PSU, and other aspects of the overall platform can definitely impact power use, and that's unfortunately something that we can't easily eliminate from the equation.
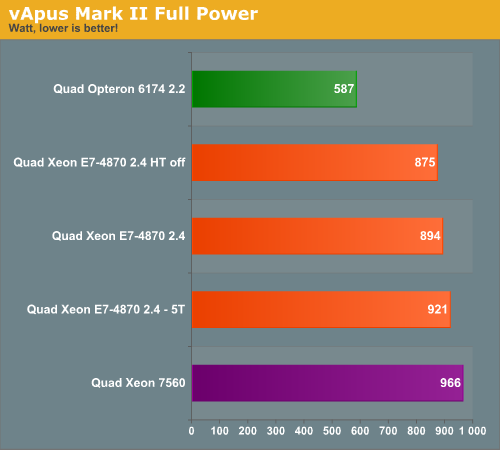
The Quad E7-4870 Xeons save about 7.5% power (894 vs 966) compared to their older brothers. The power consumption numbers look very bad compared to the AMD system in absolute terms. However, with five tiles the Quad Xeon E7 delivers 63% higher performance while consuming 57% more power. We can conclude that at very high loads, the Xeon E7 performance/watt ratio is quite competitive.
When we started testing at idle, we test with both the Samsung 1333MHz 4GB 1.35V (low power) DDR3 registered (M393B5273DH0) and 1.5V DIMMs (M393B5170FH0-H9).
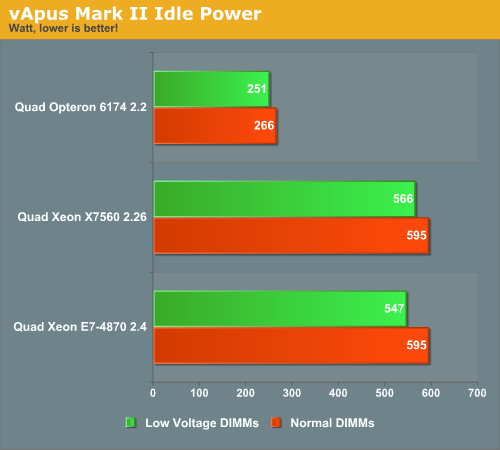
Despite the fact that the Xeon X7560 does not support low power DIMMs officially, it was able to save about 5% of the total power use. The Xeon E7's more advanced memory controller was able to reduce power by 8%. But the picture is clear: if your servers runs idle for large periods of time, the quad Opteron server is able to run on a very low amount of power, while the quad Xeon server needs at least 600W if you do not outfit it with low power 1.35V DIMMs. How much of the power difference comes from the platform in general and how much is specific to the servers being tested is unfortunately impossible to say without testing additional servers.
As we have stated before, maximum power and minimum power are not very realistic, so let us check out our real world scenario.








62 Comments
View All Comments
Fallen Kell - Thursday, May 19, 2011 - link
As the subject says. Would love to see how these deal with something like Linpack or similar.erple2 - Thursday, May 19, 2011 - link
I'd be more interested at seeing how they perform in slightly more "generic" and non-GPU optimizeable workloads. If I'm running Linpack or other FPU operations, particularly those that parallelize exceptionally well, I'd rather invest time and money into developing algorithms that run on a GPU than a fast CPU. The returns for that work are generally astounding.Now, that's not to say that General Purpose problems work well on a GPU (and I understand that). However, I'm not sure that measuring the "speed" of a single processor (or even a massively parallelized load) would tell you much, other than "it's pretty fast, but if you can massively parallelize a computational workload, figure out how to do it on a commodity GPU, and blow through it at orders of magnitude faster than any CPU can do it".
However, I can't see running any virtualization work on a GPU anytime soon!
stephenbrooks - Thursday, May 19, 2011 - link
Yeah, well, in an ideal world...But sometimes (actually, every single time in my experience) the "expensive software" that's been bought to run on these servers lacks a GPU option. I'm thinking of electromagnetic or finite element analysis code.
Finite element engines are the sort of thing that companies make a lot of money selling. They are complicated. The commercial ones probably have >10 programmer-years of work in them, and even if they weren't fiercely-protected closed source, porting and re-optimising for a GPU would be additional years work requiring programmers again at a high level and with a lot of mathematical expertise.
(There might be some decent open-source alternatives around, but they lack the front ends and GUI that most engineers are comfortable using.)
If you think fixing the above issues are "easy", go ahead. You'll make millions.
L. - Thursday, May 19, 2011 - link
lolif you code .. i don't want to read your code
carnachion - Friday, May 20, 2011 - link
I agree with you. In my experience GPU computing for scientific applications are still in it's infancy, and in some cases the performance gains are not so high.There's still a big performance penalty by using double precision for the calculations. In my lab we are porting some programs to GPU, we started using a matrix multiplication library that uses GPU in a GTX590. Using one of the 590's GPU it was 2x faster than a Phenon X6 1100T, and using both GPUs it was 3.5x faster. So not that huge gain, using a Magny-Cours processor we could reach the performance of a single GPU, but of course at a higher price.
Usually scientific applications can use hundreds of cores, and they are tunned to get a good scaling. But I don't know how GPU calculations scales with the number of GPUs, from 1 to 2 GPUs we got this 75% boost, but how it will perform using inter-node communication, even with a Infiniband connection I don't know if there'll be a bottleneck for real world applications. So that's why people still invest in thousands of cores computers, GPU still need a lot of work to be a real competitor.
DanNeely - Saturday, May 21, 2011 - link
single vs double precision isn't the only limiting factor for GPU computing. The amount of data you can have in cache per thread is far smaller than on a traditional CPU. If your working set is too big to fit into the tiny amount of cache available performance is going to nose dive. This is farther aggravated by the fact that GPU memory systems are heavily optimized for streaming access and that random IO (like cache misses) suffers in performance.The result is that some applications which can be written to fit the GPU model very well will see enormous performance increases vs CPU equivalents. Others will get essentially nothing.
Einstein @ Home's gravitational wave search app is an example of the latter. The calculations are inherently very random in memory access (to the extent that it benefits by about 10% from triple channel memory on intel quads; Intel's said that for quads there shouldn't be any real world app benefit from the 3rd channel). A few years ago when they launched cuda, nVidia worked with several large projects on the BOINC platform to try and port their apps to CUDA. The E@H cuda app ended up no faster than the CPU app and didn't scale at all with more cuda cores since all they did was to increase the number of threads stalled on memory IO.
Marburg U - Thursday, May 19, 2011 - link
Finally something juicy,JarredWalton - Thursday, May 19, 2011 - link
So, just curious: is this spam (but no links to a separate site), or some commentary that didn't really say anything? All I've got is this, "On the nature of things":http://en.wikipedia.org/wiki/De_rerum_natura
Maybe I missed what he's getting at, or maybe he's just saying "Westmere-EX rocks!"
bobbozzo - Monday, May 23, 2011 - link
Jarred, my guess is that it is spam, and that there was a link or some HTML posted which was filtered out by the comments system.Bob
lol123 - Thursday, May 19, 2011 - link
Why is there a 2 socket only line of E7 (E7-28xx), but at least as far as I can tell, not any 2-socket motherboards or servers? Are those simply not available yet?